
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- cv
- Unreal Engine
- 디퓨전모델
- motion matching
- Generative Model
- deep learning
- Few-shot generation
- GAN
- UE5
- WBP
- 폰트생성
- 오블완
- 생성모델
- ue5.4
- 모션매칭
- 딥러닝
- WinAPI
- ddpm
- 언리얼엔진
- userwidget
- Stat110
- Font Generation
- NLP
- dl
- animation retargeting
- multimodal
- CNN
- Diffusion
- BERT
- RNN
Archives
- Today
- Total
Deeper Learning
Few-shot Font Generation with Localized Style Representations and Factorization 본문
AI/Deep Learning
Few-shot Font Generation with Localized Style Representations and Factorization
Dlaiml 2021. 9. 19. 18:32Abstract
- 기존 Few-shot font generation 모델은 style과 content의 disentanglement을 하고자 하였지만 이와 같은 접근법은 다양한 "local styles"을 표현하는데 한계가 있다
- 이는 복잡한 letter system(ex. Chinese)에 적합하지 않다
- localized styles = component-wise style representations을 학습하는 방식으로 font generation하는 모델을 제안
- reference glyph의 수를 줄이기위해 component-wise style을 component factor와 style factor의 product으로 정의한다.
- strong locality supervision (component의 위치 정보 등)을 사용하지 않고 8개의 reference glyph images로 SOTA보다 좋은 결과
Introduction
- 목표는 high-quality, diverse styles의 fine-tuning이 아닌 few-shot font 생성
- 기존 few-shot font generation은 각 font의 universal style을 학습한다.
- 기존 방식으로 glyph-rich script에서 full font 생성 시 다양한 local style을 표현하지 못하는 문제가 발생
- DM Font는 같은 문제를 지적하며 Component-wise local features를 한번에 추출하여 Dynamic memory와 Persistent memory에 저장한다.
- DM Font는 완전한 조합형 글자인 한글, 태국어에 국한되어있다는 문제가 있다.
- DM Font는 중국어의 복잡한 조합성으로 인한 complex glyph structure와 diverse local style 학습에 실패하였다.
- DM Font는 모든 글자가 memory를 형성하기 위해 최소 1번은 reference set에 등장하여야 한다는 문제가 있다.
- universal이 아닌 localized style representation을 학습하는 LF-Font를 제시
- localized style representation == character-wise style feature that considers both a complex character structure and local styles
- component-wise local style representation 조합이 glyph의 local style
- factorization module을 활용 → entire components가 reference set에 없어도 생성 가능
Few-shot Font Generation with Localized Style Representations and Factorization

- U_c = {u_1, u_2, u_3 , ..., u_m}으로 m은 해당 character의 component 수가 된다.

- common framework of font generation
- reference set X_r에서 Style Encoder E_s를 사용하여 추출한 style representation f_s와 source style s_0의 character c glyph에서 Content Encoder E_c를 사용하여 추출한 content representation f_c를 Generator에 주어 생성 글자 x_sc를 만든다.
- 위 수식의 f_s는 style s의 universal style이라고 가정한다. 하지만 이러한 가정은 complex local style을 간과하는 것이며 unseen style에서 좋은 결과를 내지 못한다.
- 우리는 Style Encoder E_s를 character-wise style을 encoding 하도록 디자인 하였다.
- 하지만 모든 character-wise style을 handling하는 것은 어렵다. (Chinese has huge character vocab size over 20,000)
- character를 combination of multiple component로 표현: Character label c 대신 Component set U_c를 사용
- 기존 f_s = E_s(X)를 f_su = E_s(X, u)로 변경 (Component set U의 style을 encoding하는 형태)
- component-wise features f_s,u를 더하여 character-aware localized style feature f_sc를 계산

- reference set에 존재하는 component만 생성이 가능하므로 reference set이 모든 component set을 cover해야 few-shot font generation의 달성이 가능하다.
- 위 문제를 해결하기 위해 few-shot generation 문제를 reconstruction problem으로 보았다. few style-component pair만 보고 missing style-component pair를 reconstruct하도록 설계하였다.
- component-wise style feature f_su (k dim)를 two factor로 decompose
- component factor z_u (k*d dim)
- style factor z_s (k*d dim)
- k = dimension of factors
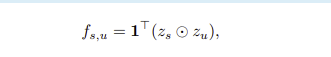
- factorization의 computational cost를 줄이기 위해 style(content) factorization module F_s(c)를 사용

- Factorization module의 linear weight W, b를 사용하여 각 factor를 아래의 식처럼 계산한다.

- same style이지만 다른 glyph set을 사용하여 만든 output style factor는 동일해야 한다. 이를 위해 Consistency loss를 사용한다. (content에 대해서도 마찬가지)

- mu_s는 style s의 모든 component set에 대한 평균 style factor
- mu_u는 component set u의 모든 style set에 대한 평균 component factor
- consistent loss를 통해 style s, component set u의 style factor는 mu_s에 가까워진다. (component에 대해서도 동일)
- 학습이 완벽하게 되면 이론상 style factor z_s는 1개의 reference glyph에서 뽑아내도 style s를 완벽하게 나타낼 수 있게 된다.

Style Encoding
- Component-wise style encoder E_su
- style, content factorization module F_s, F_c
- E_su로 encoding된 component-wise style featrue f_su는 factorization module에 의해 z_s, z_u로 factorized
- reference set의 style factor z_s_tilde와 source glyph의 component factor z_u를 결합하여 re-stylized component-wise feature f_s_tilde_u를 만든다.
- reference glyph이 여러개면 각 glyph에서 뽑아낸 style factor를 평균내어 최종 style factor를 구한다.
Content Encoding
- Complex global structure를 학습하기 위한 part
- component set의 one to many problem을 해결
- Content encoder E_c는 source glyph의 complex global structure(e.g., relative locations of components)를 학습
- strong localization supervision 없이 source glyph의 complex structural information을 보존하며 target glyph을 생성
Training
- Style Encoder E_su, Factorization modules F_c, F_u, generator G를 학습시켜야한다.
- source style s_0을 고정하고 학습 (complex structural information을 제공하기 위함)
- Adversarial loss
- style, content 측면에서 그럴듯한 글자를 만들기 위해 사용하는 loss
- multi-head conditional discriminator를 사용
- hinge GAN loss 사용

- L1 loss and feature matching loss
- generated glyph, groud truth glyph의 pixel-level feature-level loss 측정
- L = num of layers in discriminator

- Component-classification loss
- component-wise classifier Cls를 사용하여 component-wise style feature f_su의 label u를 classify
- Cross entropy사용
- 첫째 항은 reference glyph x_s_c_tilde 관련 식, 둘째 항은 generated glyph x_tilde_s_c 관련 식


- lambda_L1 = 1.0, 나머지는 0.1을 사용하여 실험하였다.
Experiments
- Combined 형식으로 학습 시킨 후 Factorization 도입
DM-Font와 마찬가지로 Few-shot을 달성하기 위해 Compositionality에 집중하였지만 Factorization module을 사용하여 추가적인 disentanglement를 유도
Reference
[1] Few-shot Font Generation with Localized Style Representations and Factorizations, https://arxiv.org/abs/2009.11042
'AI > Deep Learning' 카테고리의 다른 글
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.09.20 |
|---|---|
| Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts (0) | 2021.09.19 |
| CS231n - Lecture 8 ~ 13 (0) | 2021.09.11 |
| Few-shot Compositional Font Generation with Dual Memory (0) | 2021.09.01 |
| CS231n - Lecture 5 ~ 7 (0) | 2021.09.01 |
'AI/Deep Learning' Related Articles
more




Comments