
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- GAN
- CNN
- Few-shot generation
- UE5
- ue5.4
- 오블완
- dl
- 폰트생성
- 모션매칭
- multimodal
- WinAPI
- Unreal Engine
- 언리얼엔진
- BERT
- RNN
- WBP
- cv
- Diffusion
- deep learning
- Generative Model
- 디퓨전모델
- Font Generation
- userwidget
- Stat110
- animation retargeting
- ddpm
- 딥러닝
- motion matching
- 생성모델
- NLP
- Today
- Total
Deeper Learning
CS231n - Lecture 8 ~ 13 본문
복습이므로 전체적인 내용 리뷰가 아닌 그룹 스터디 중 토론 나눴던 주제 중심으로 정리.
이해하였던 내용을 떠올릴 수 있을 정도로만 정리
Lecture 8

Lecture 9
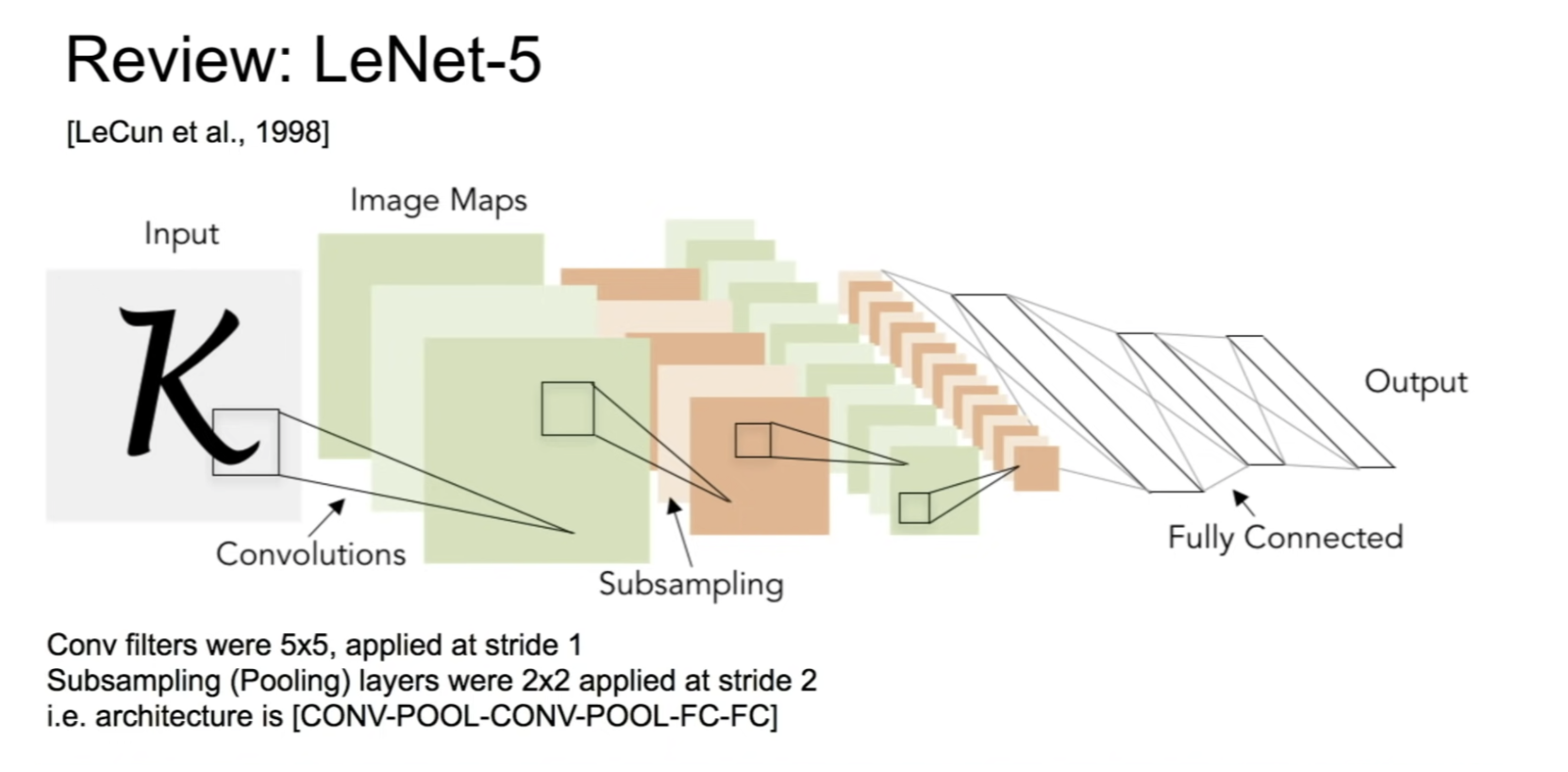
LeNet-5
- conv - pool - conv - pool - fc -fc 형식의 모델
- 1998년 yann lecun

AlexNet
- ILSVRC에서 작년에 비해 엄청난 성능 향상으로 winner
- CNN을 활용하는 method가 이후 활발하게 연구
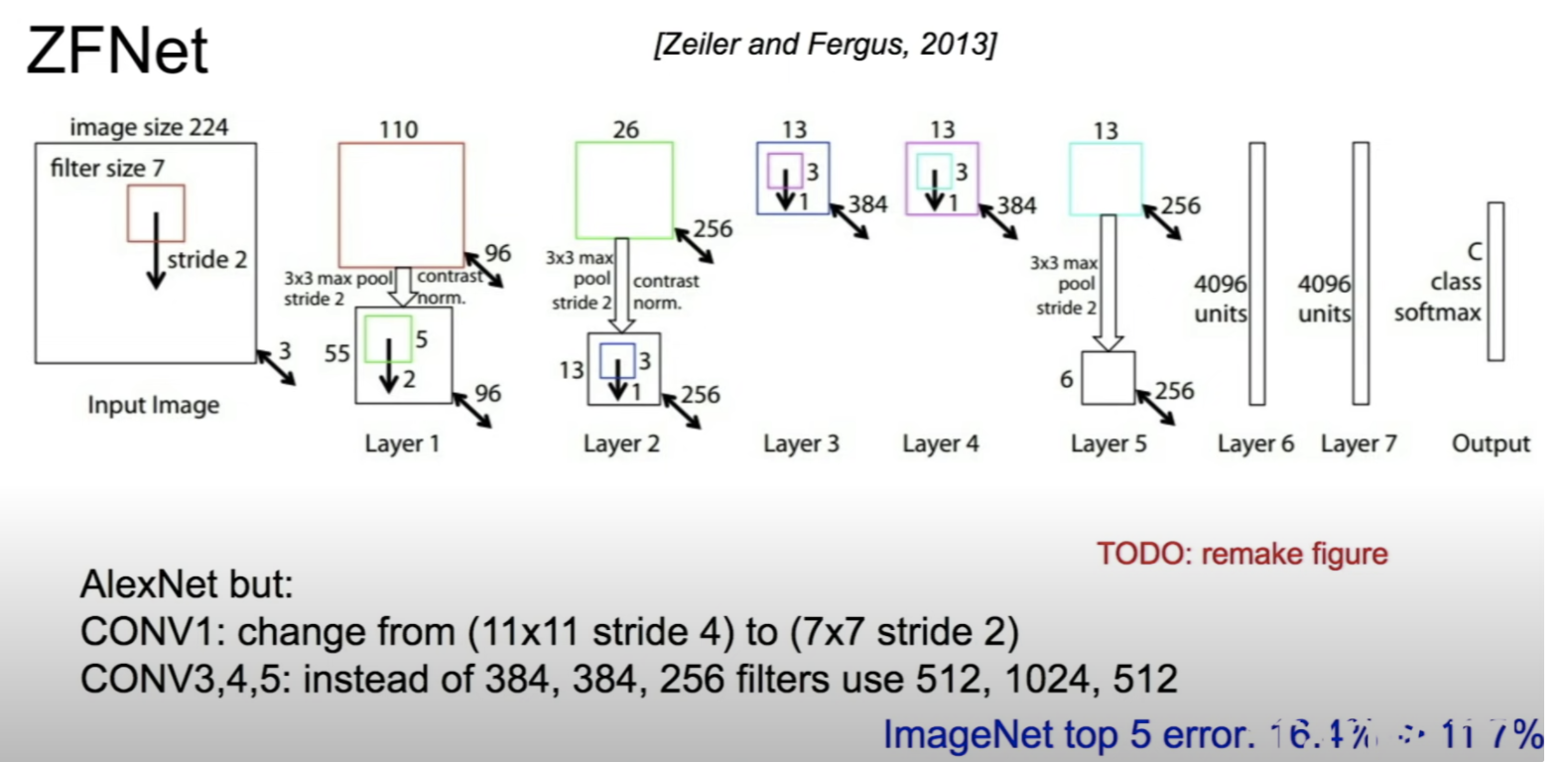
ZFNet
- AlexNet과 매우 유사한 구조, kernel, filter, stride 등 hyperparameter를 조정
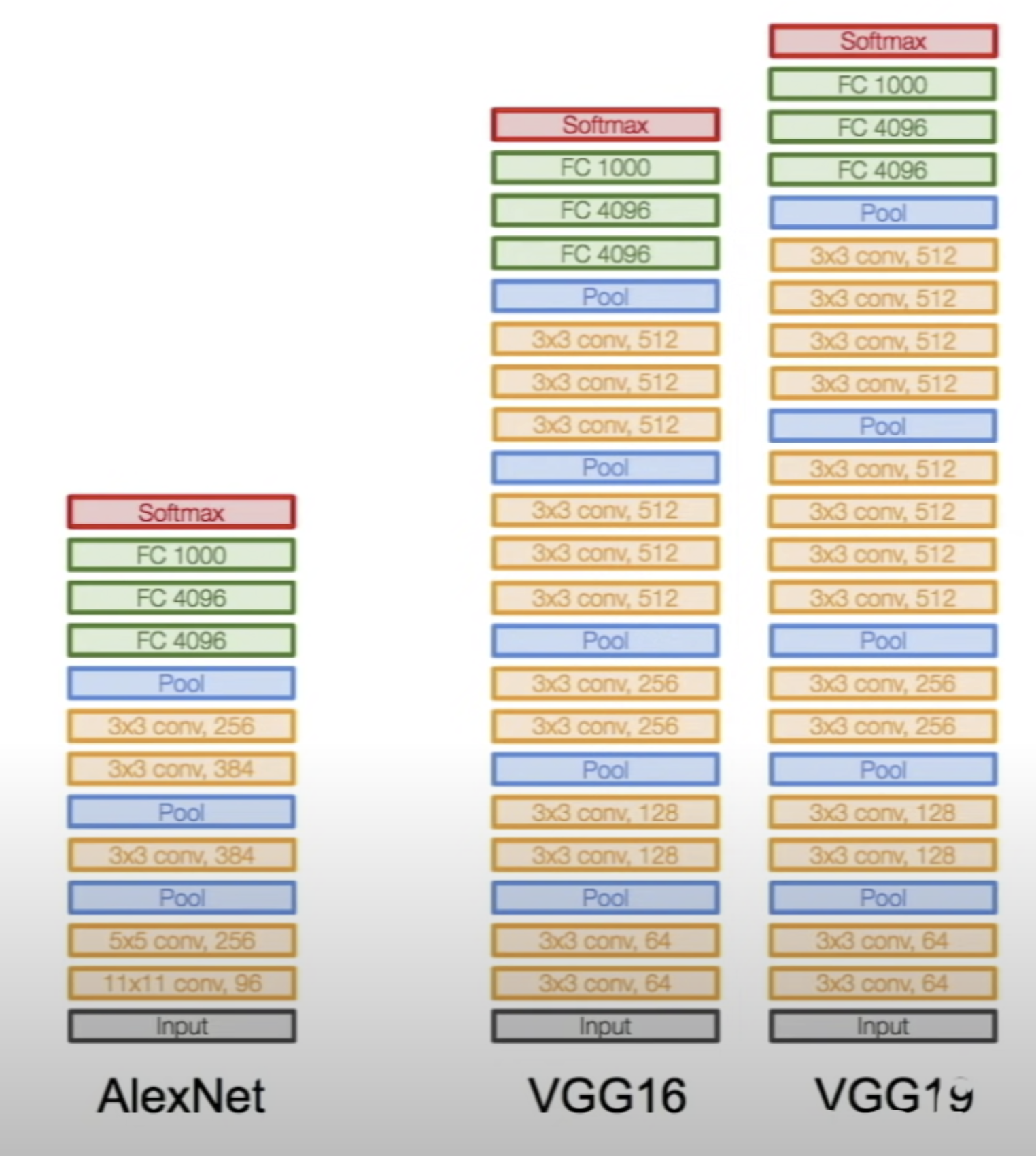
VGGNet
- 11x11 kernel을 사용하지 않고 3x3 kernel로만 깊게 layer를 구성
- 3x3 kernel을 깊게 쌓아 large receptive field, few parameter
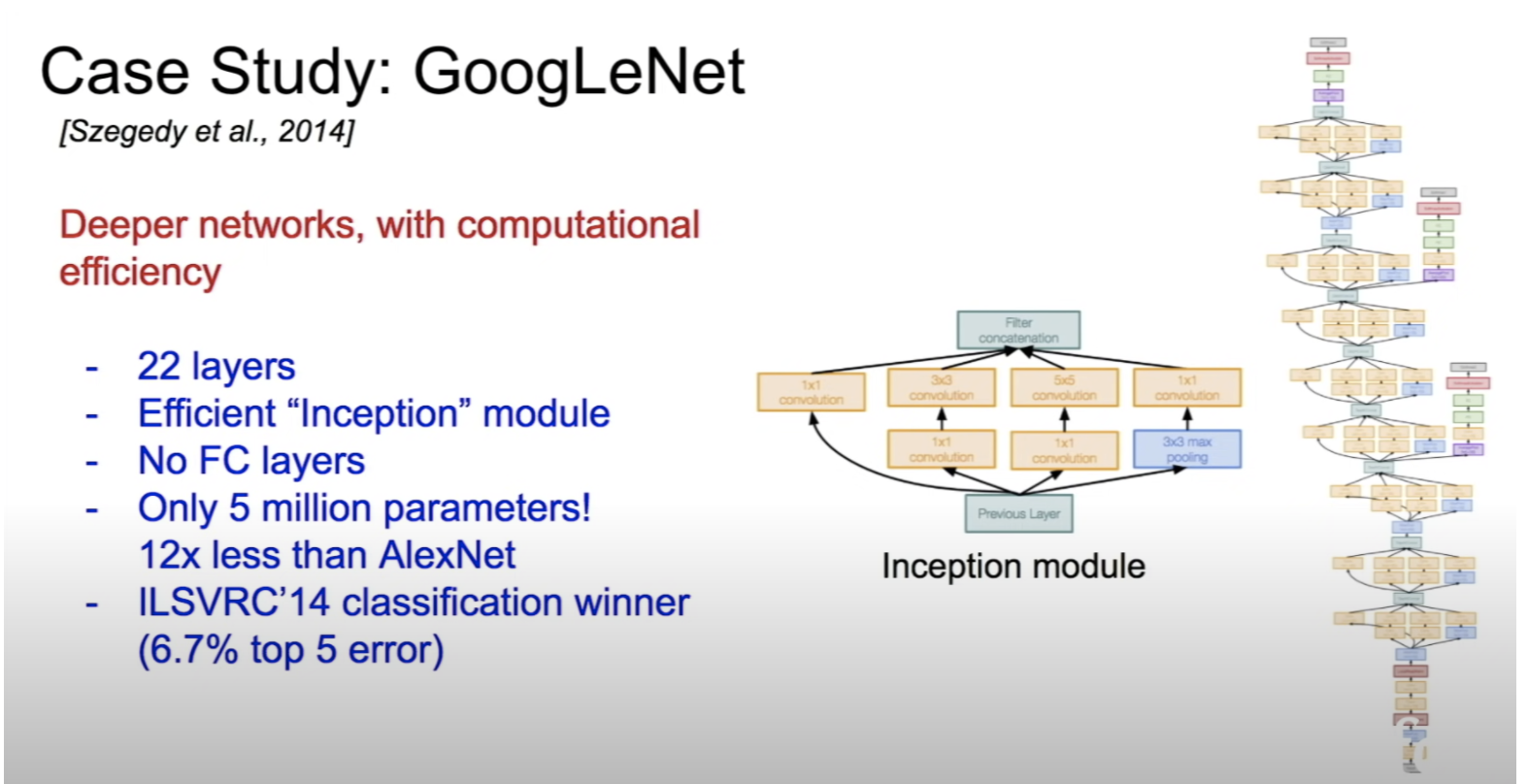
- 구글에서 발표한 모델
- Inception module을 사용
- 여러 측면에서 input을 해석한다는 직관적 해석
- pooling layer로 preserve되는 차원을 줄이고 spatial 정보를 보존하기 위해 1x1 conv 사용
- gradient vanishing 문제를 해결하기 위해 auxiliary classifier를 중간에 삽입하여 loss를 전달
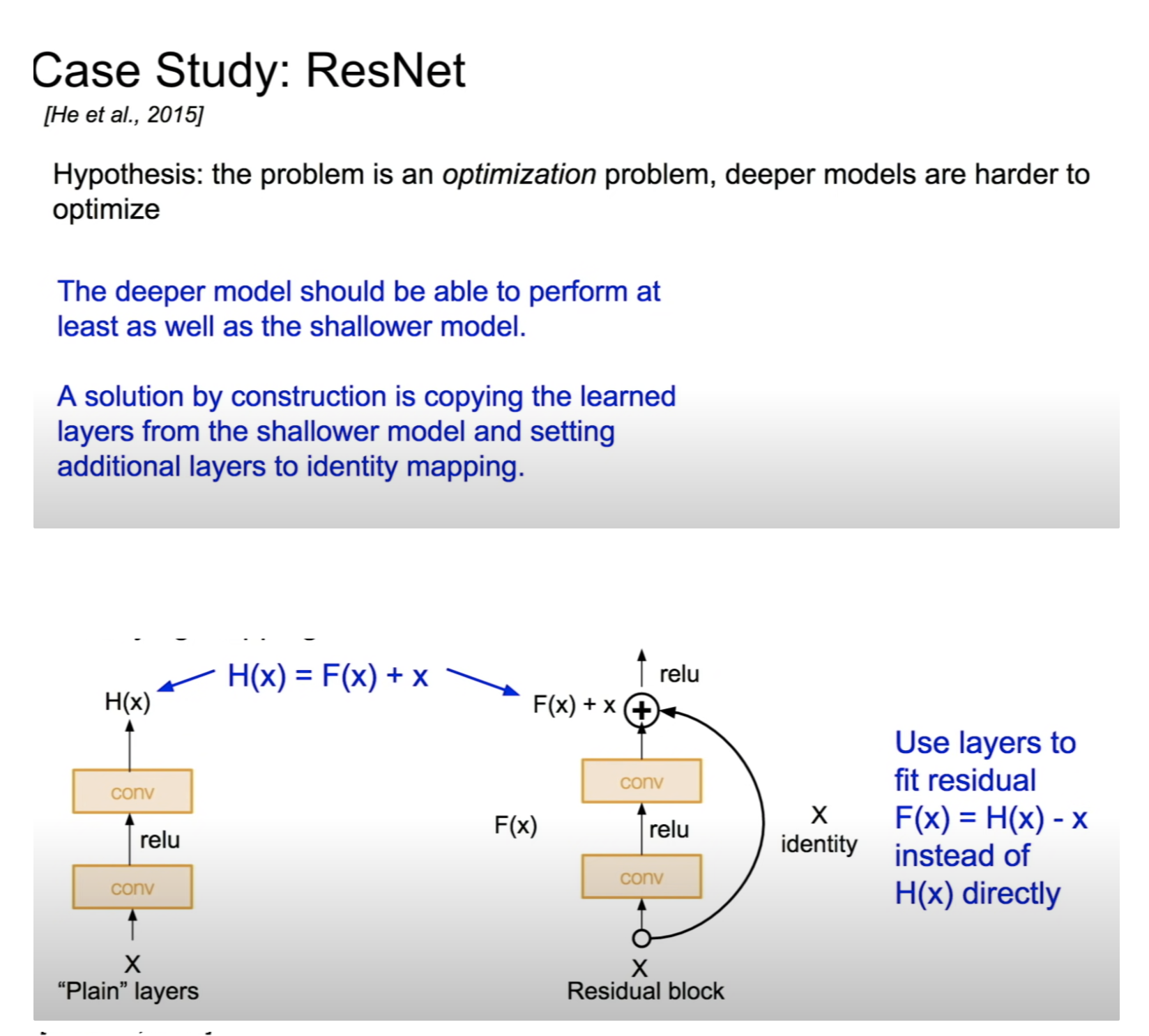
ResNet
- 잔차를 학습
- 논문 스터디 내용 바탕으로 자세하게 작성 예정

- bottleneck 사용
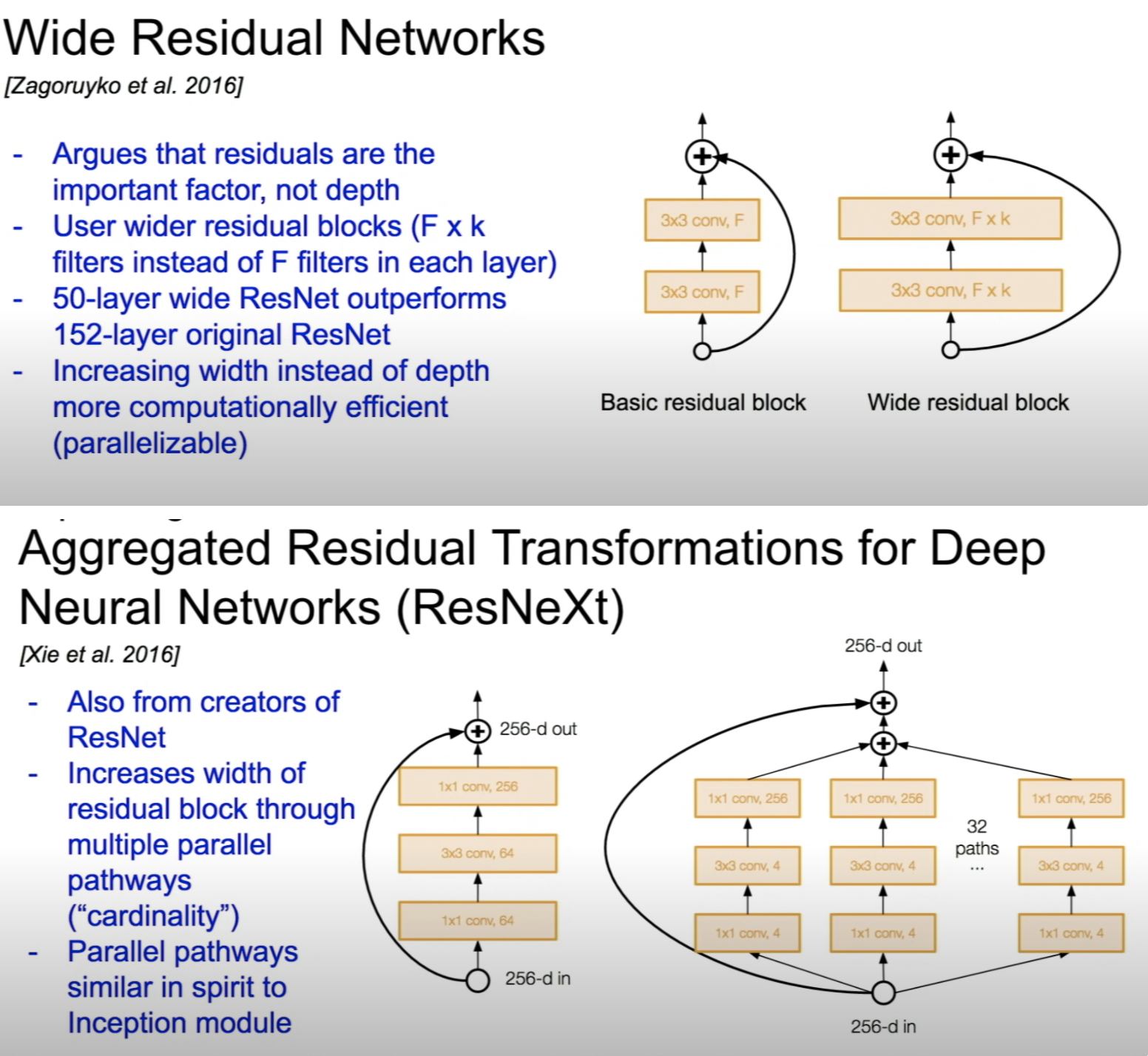
WideResNet
- depth보다 width를 늘린 모델로 computational cost가 적다
- ResNet에서 residual connection을 가져가고 depth를 버린 형태의 모델, 50-layer wide ResNet은 152-later ResNet보다 성능이 좋음
ResNeXt
- multiple parallel pathways를 사용하여 residual block의 width를 늘림
- Inception 모듈과 비슷
위 2개의 모델은 베이스라인으로 많이 사용

Deep Networks with Stochastic Depth
- gradient vanishing 문제를 depth를 확률적으로 줄이며 해결
Lecture 10
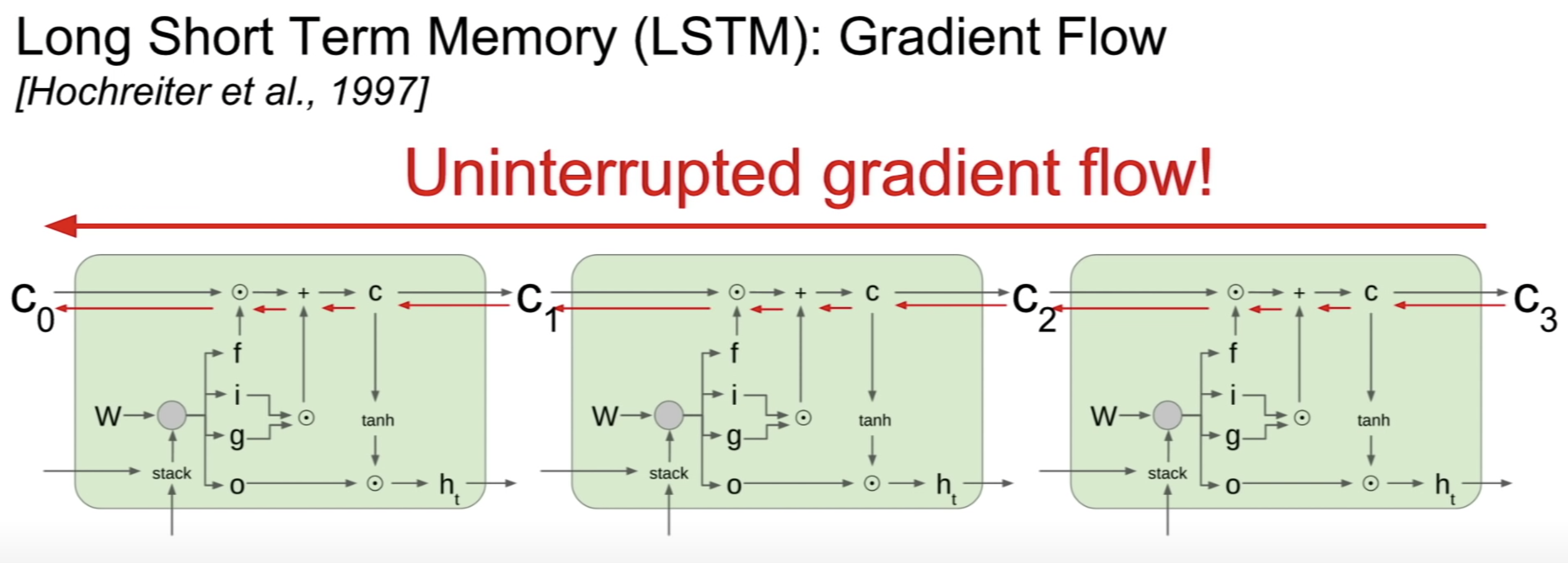
CS224n에서 자세하게 저술 예정
Lecture 11
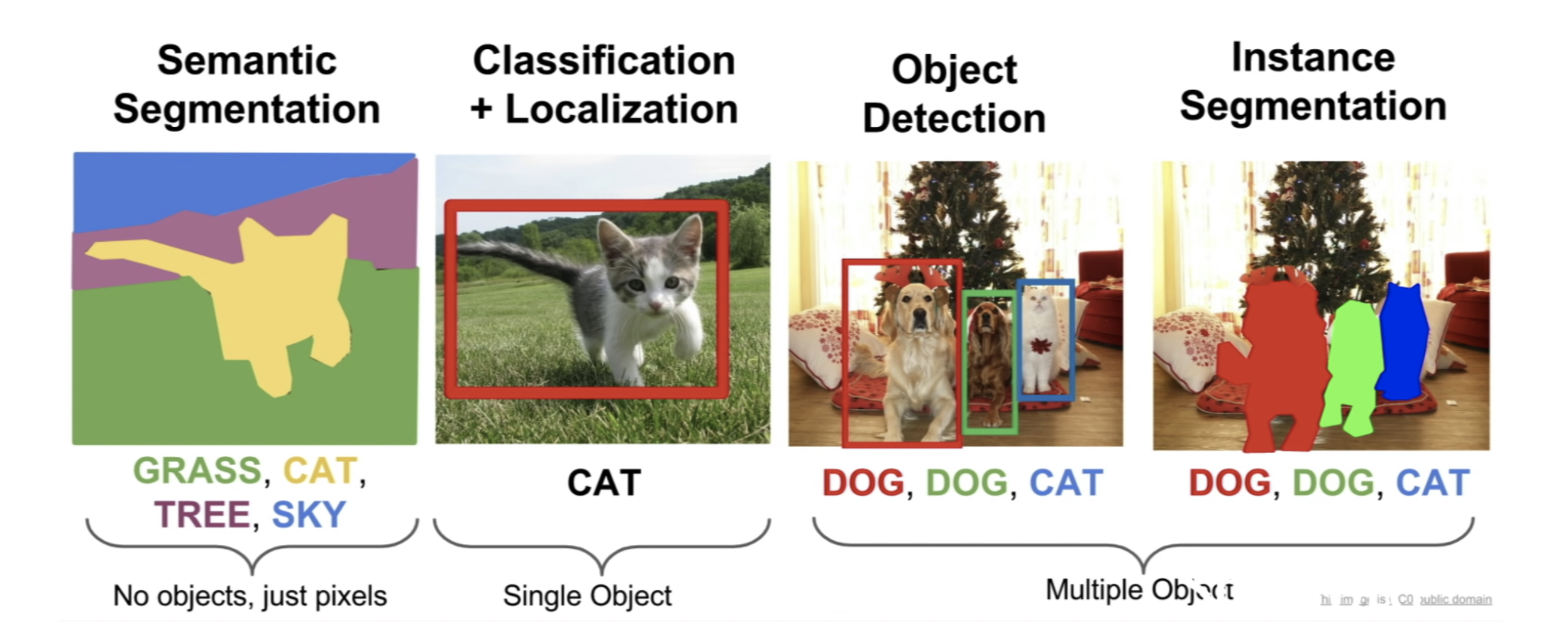
Semantic Segmentation
- 모든 pixel을 categorize하는 형태
- instance의 개념이 없음, only care pixels
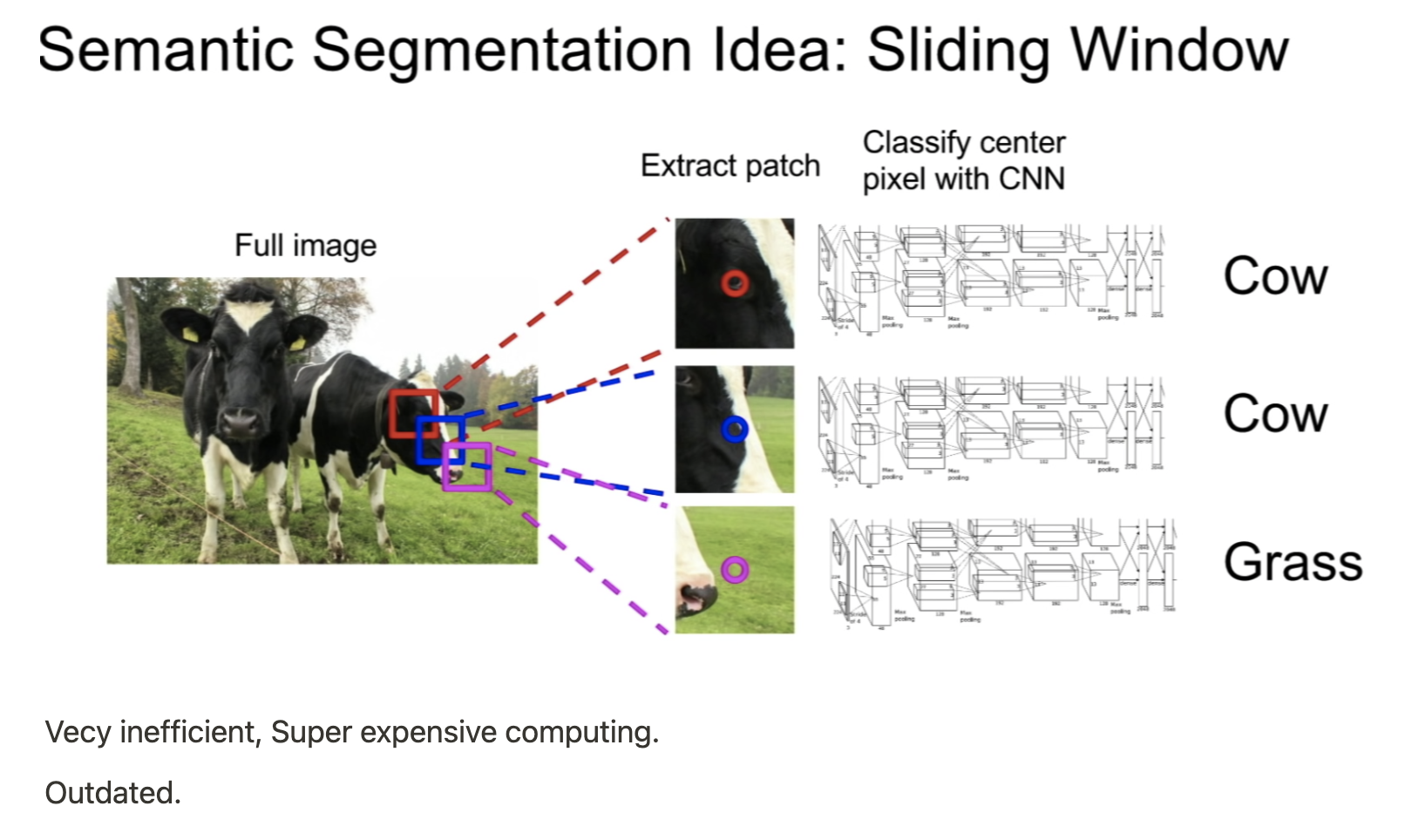
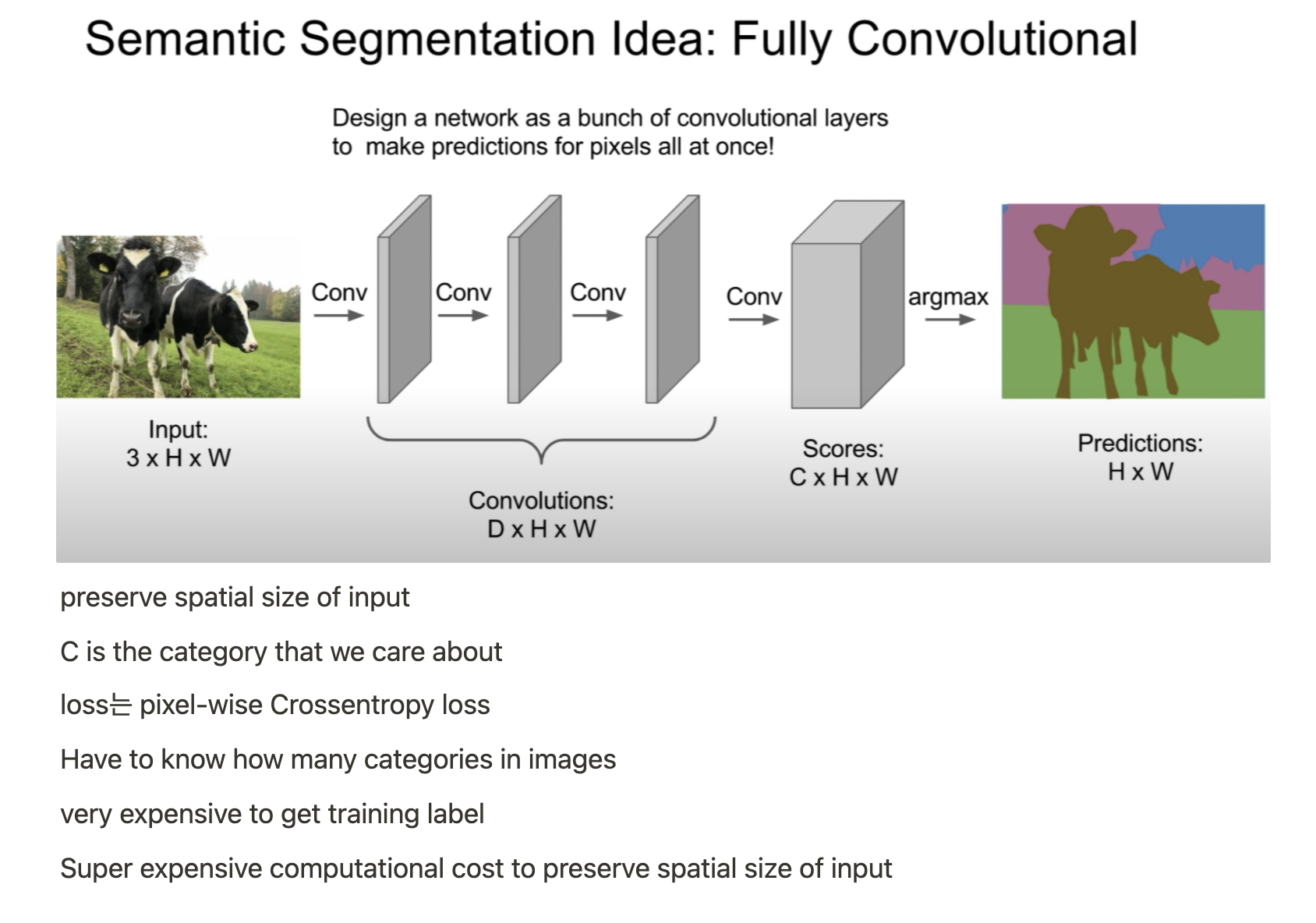
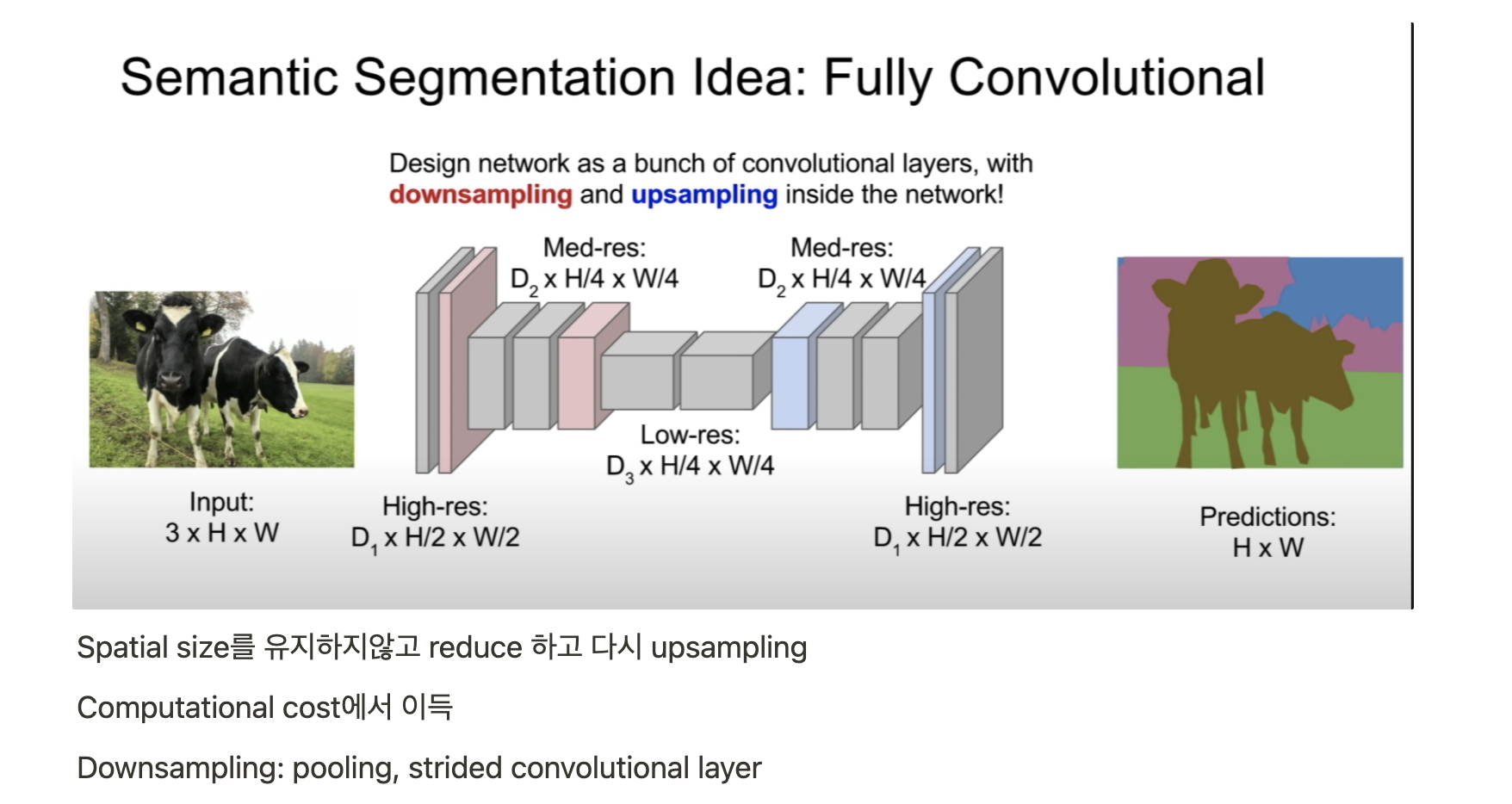
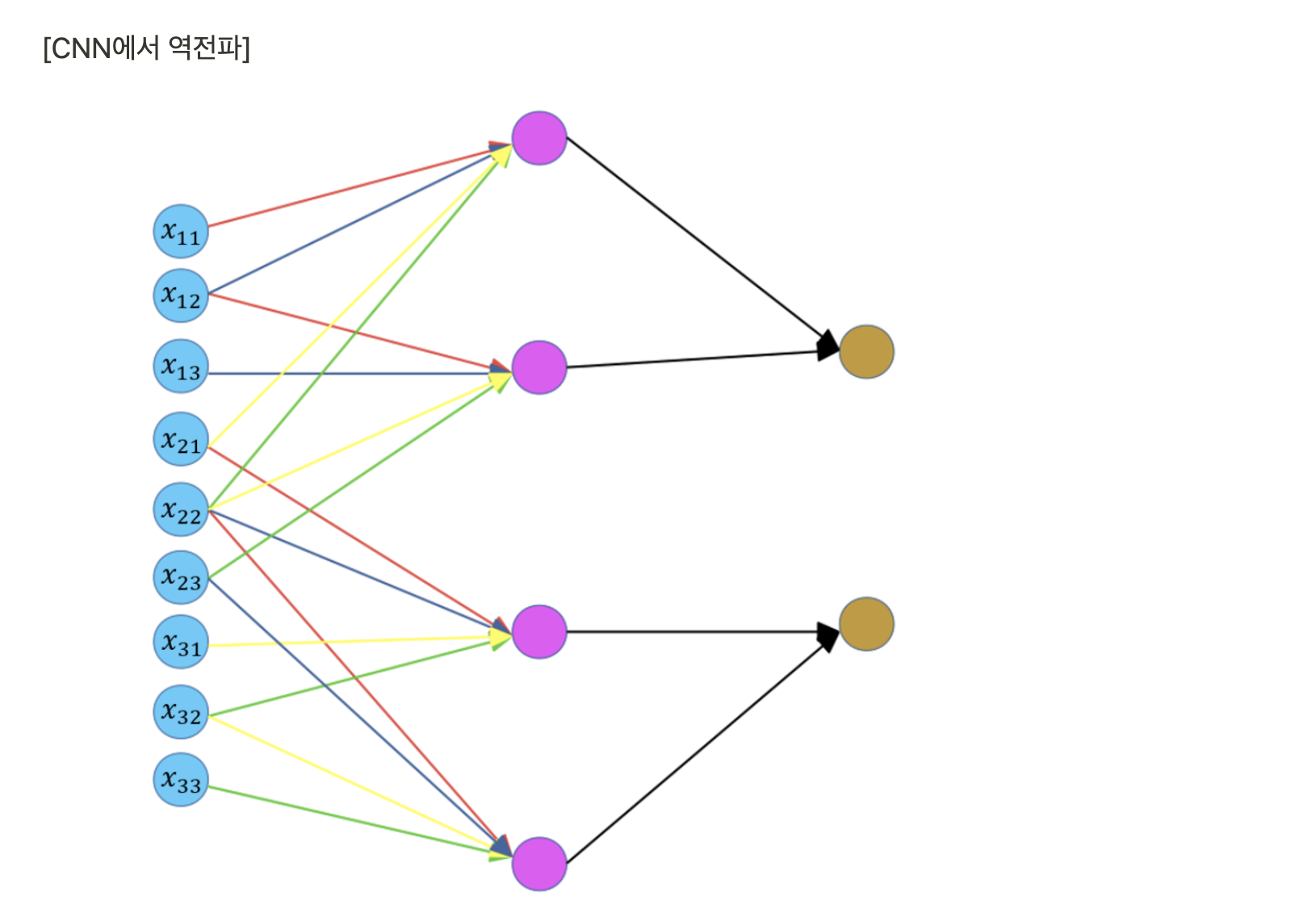
- CNN은 Dense connection이 아니며 각 kernel의 weight는 특정 input과 계산된다.
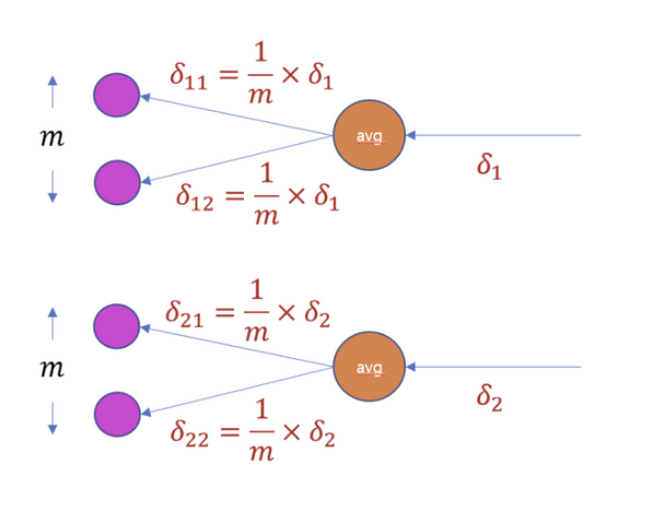
- Average pooling의 역전파는 위 그림과 같다. y = (a + b) / 2를 a에 대해 직접 미분해보면 1/2가 남는다.
- Average pooling layer의 local gradient는 1/m이 된다.
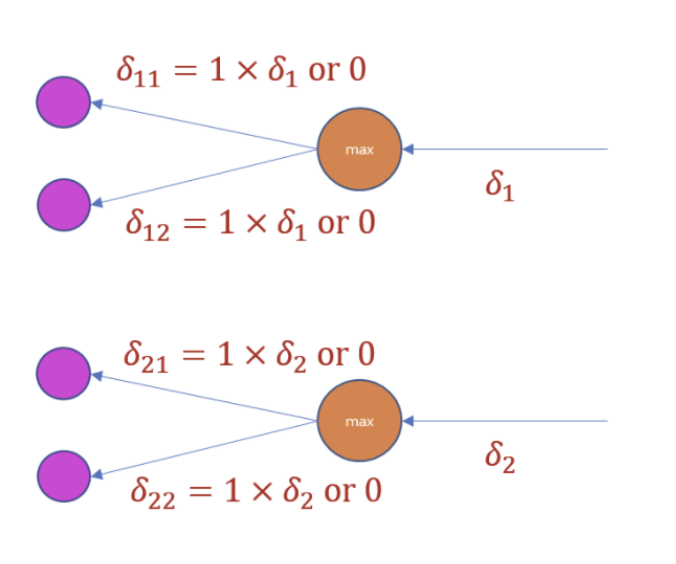
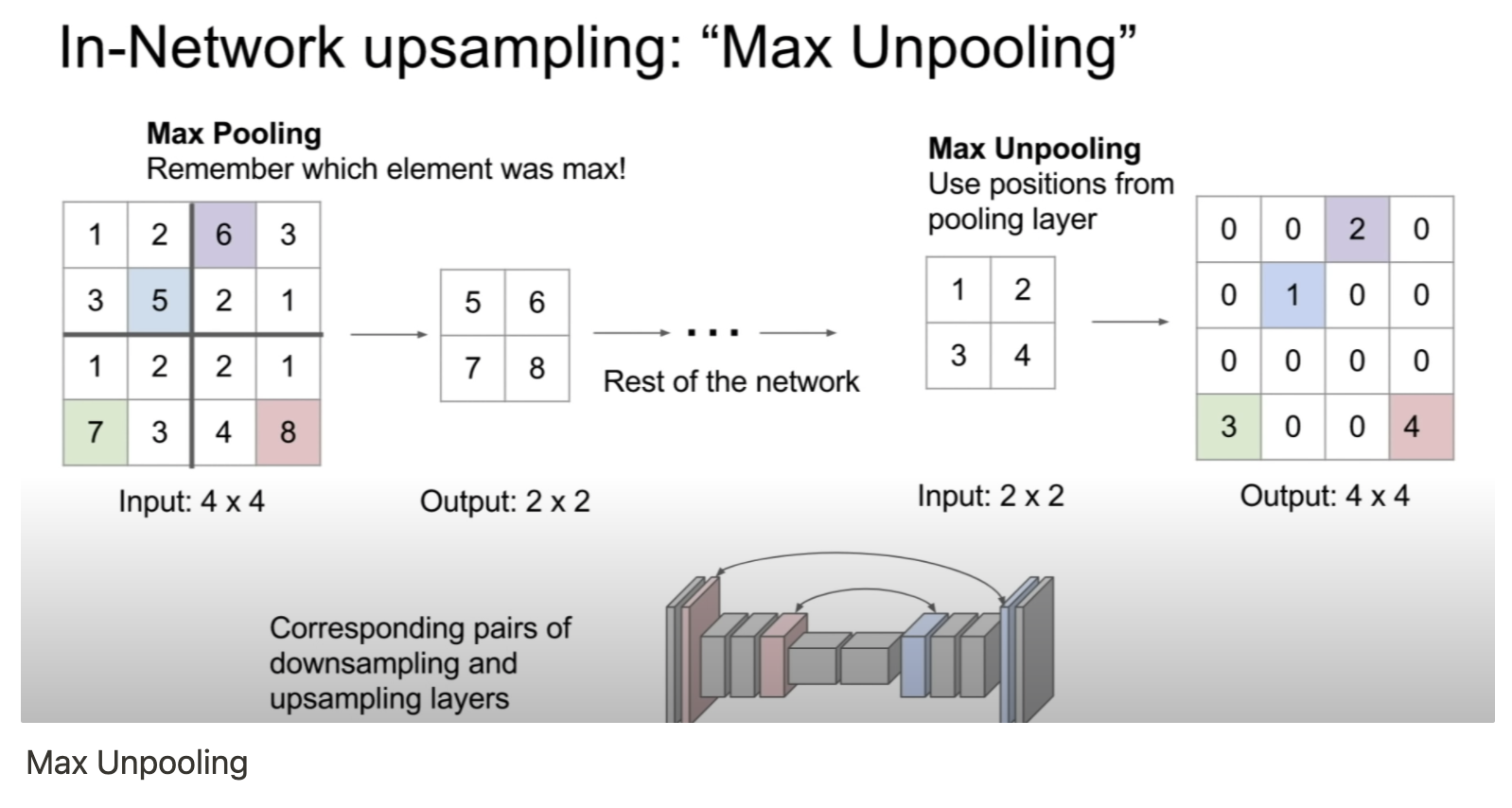
- MaxPooling layer의 역전파는 위와 같다
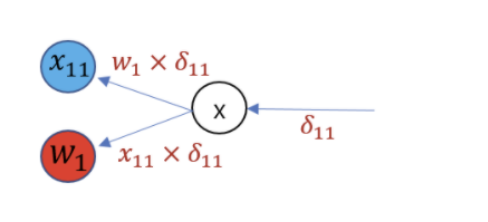
- Conv layer의 역전파도 복잡해 보이지만 수식으로 정리하면 매우 간단하다.
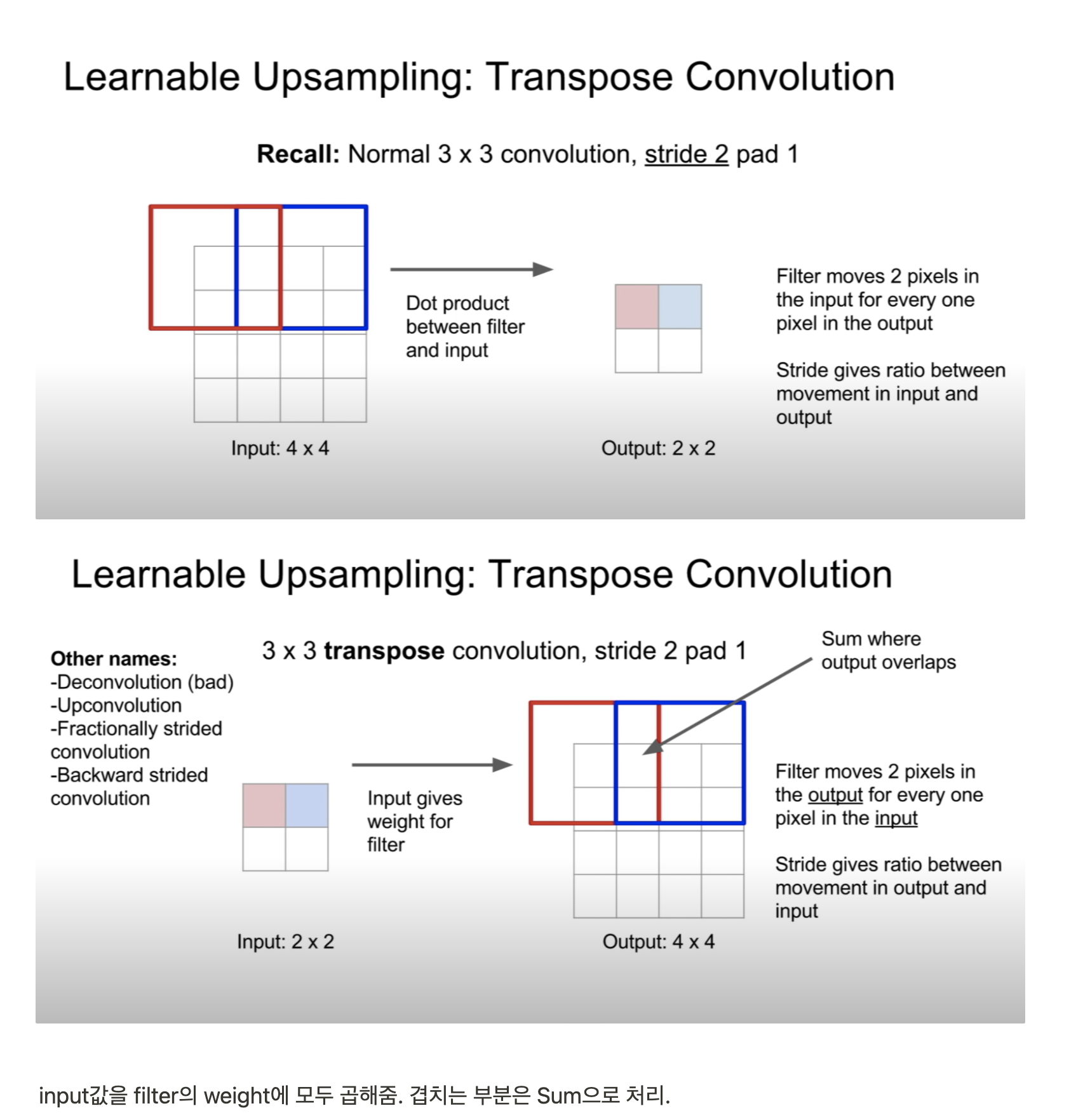
Encoder, Decoder 구조로 이루어진 생성모델에서 Transpose Convolution은 체커보드 패턴이 발생하는 문제가 있다
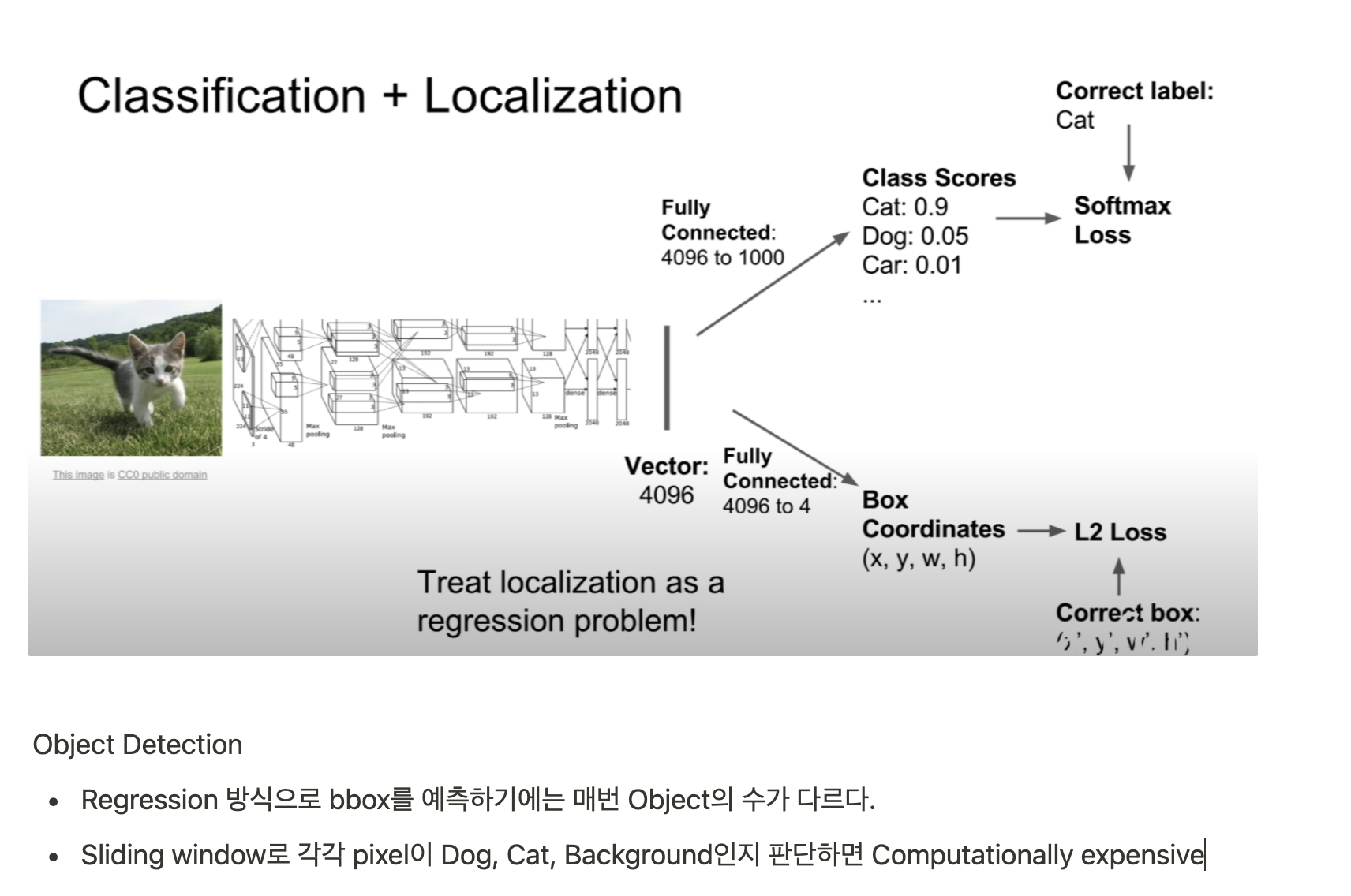

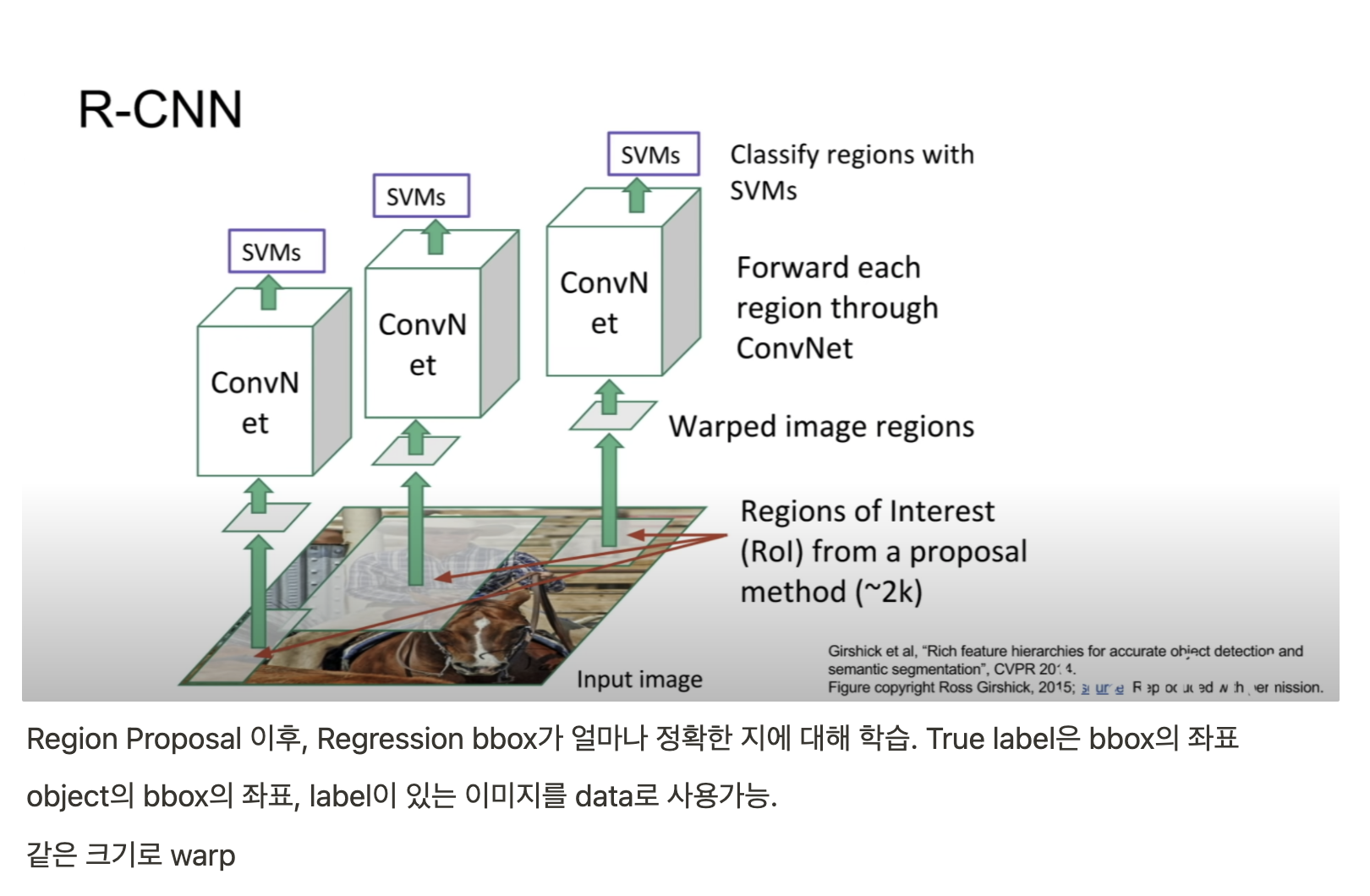


CNN Classifier가 아닌 SVM을 사용한 이유는 성능이 더 좋았기 때문 (위치정보 유실로 인한 cnn의 성능저하로 저자는 해석)
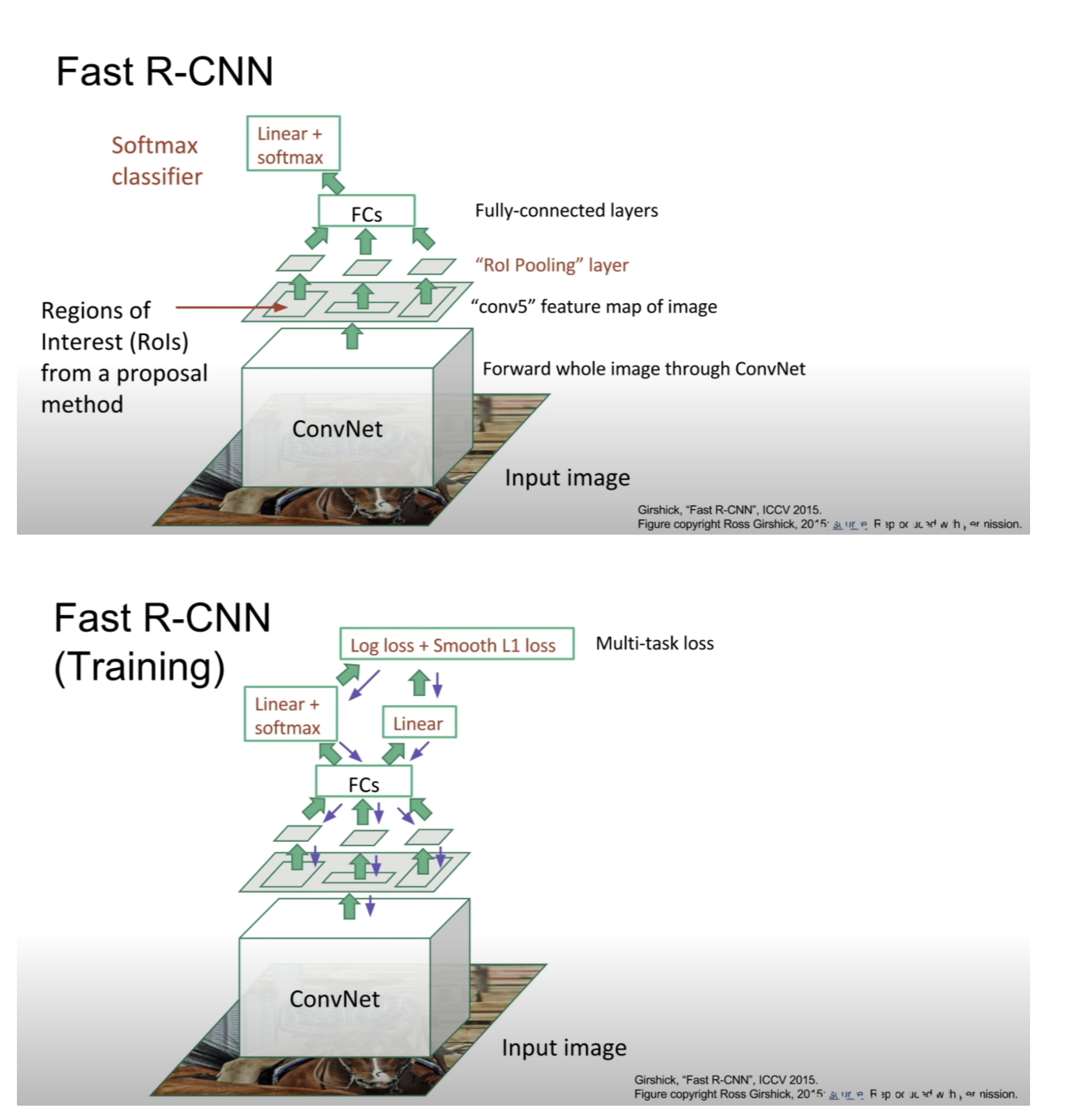
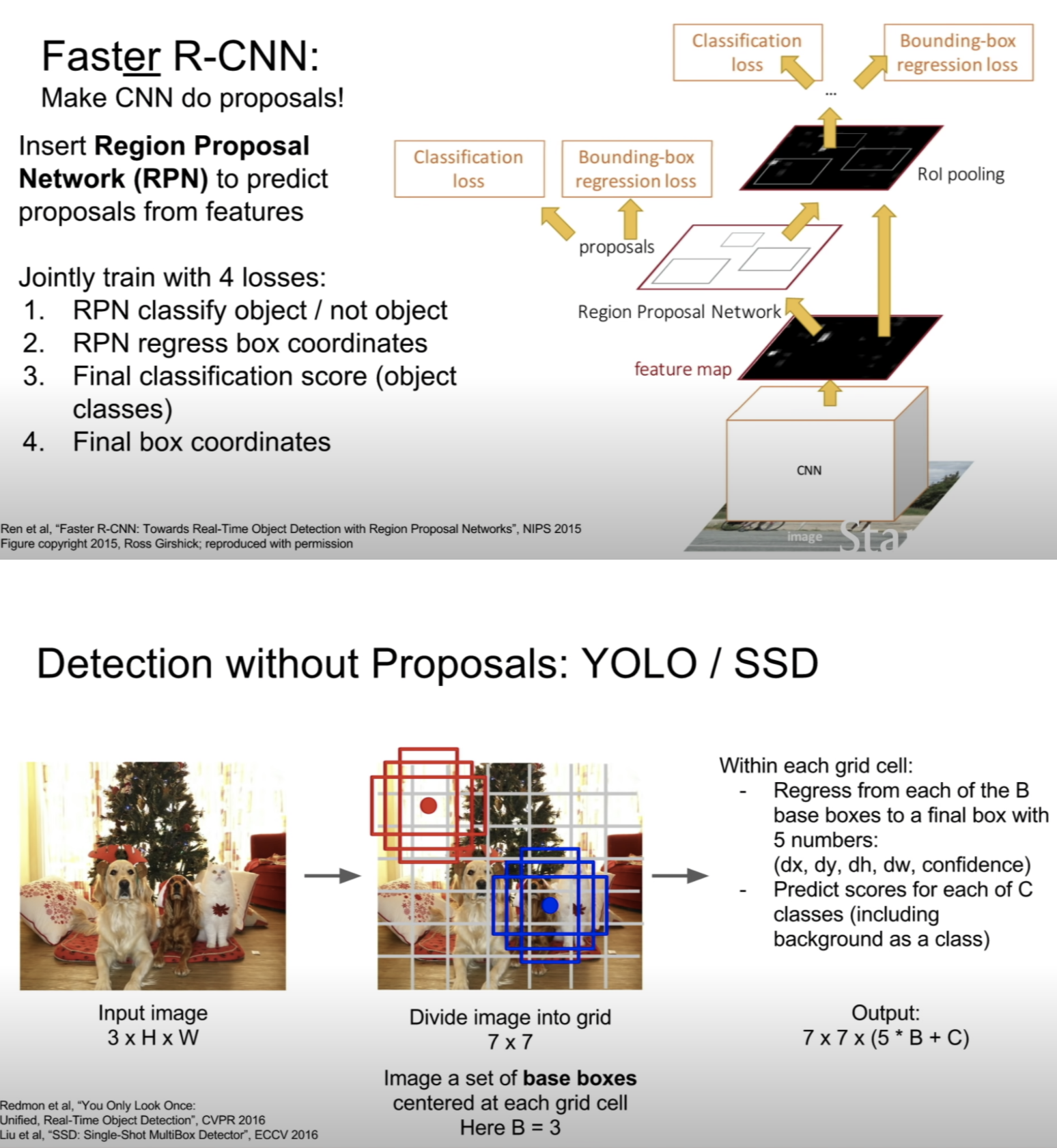
위 object detection 알고리즘에 대해서는 따로 정리 with 코드
Lecture 12





Softmax Score를 최대화 시키도록 image pixel or 다른 층을 Gradient Ascent를 사용하여 update

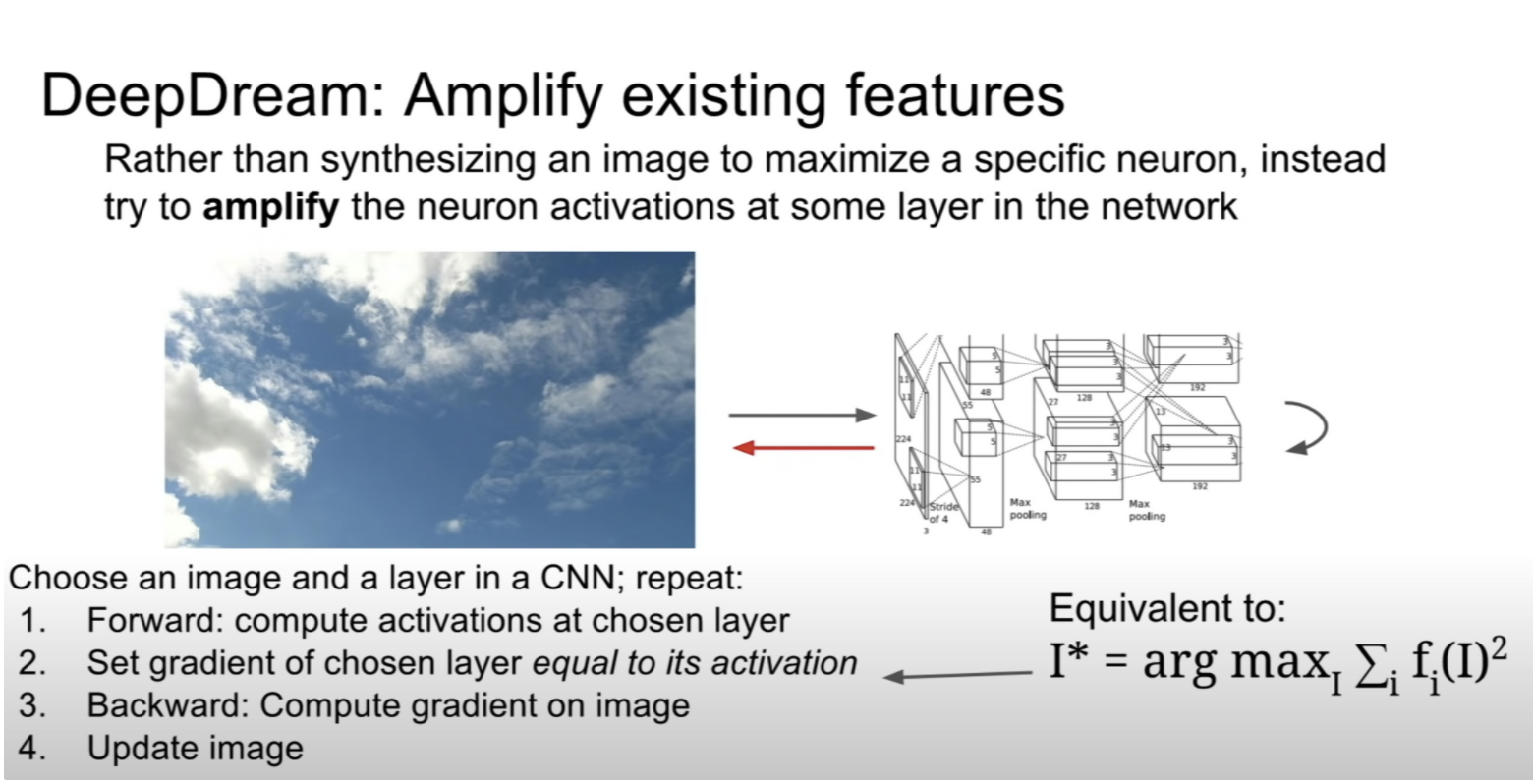
activation을 gradient로 설정하여 layer의 activation이 최대가 되도록 image를 update
exact 이미지가 아닌 noise를 준 jittered image를 input으로 주는 경우 좋은 성능을 보인다.
Clip pixel value도 도움이 된다.


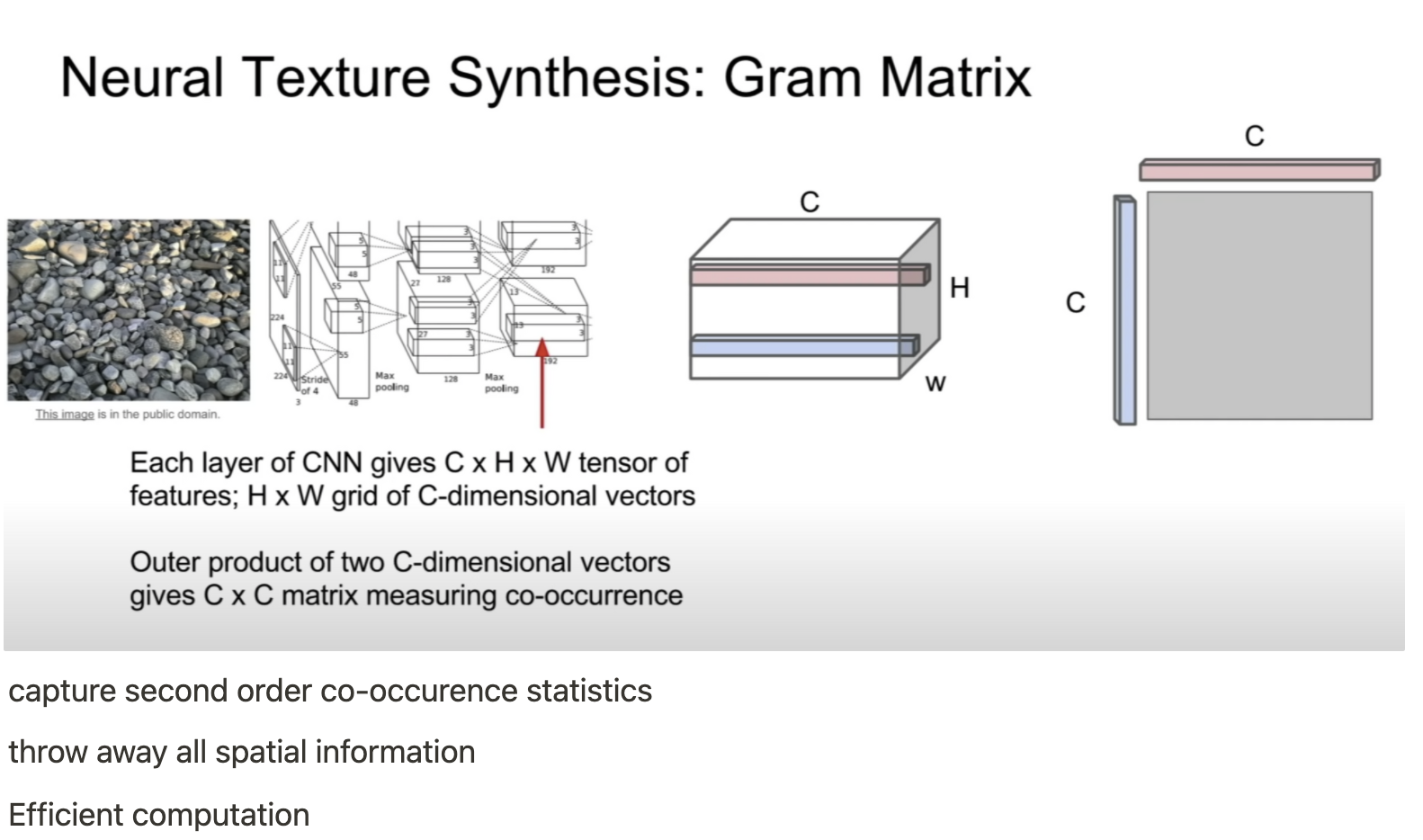
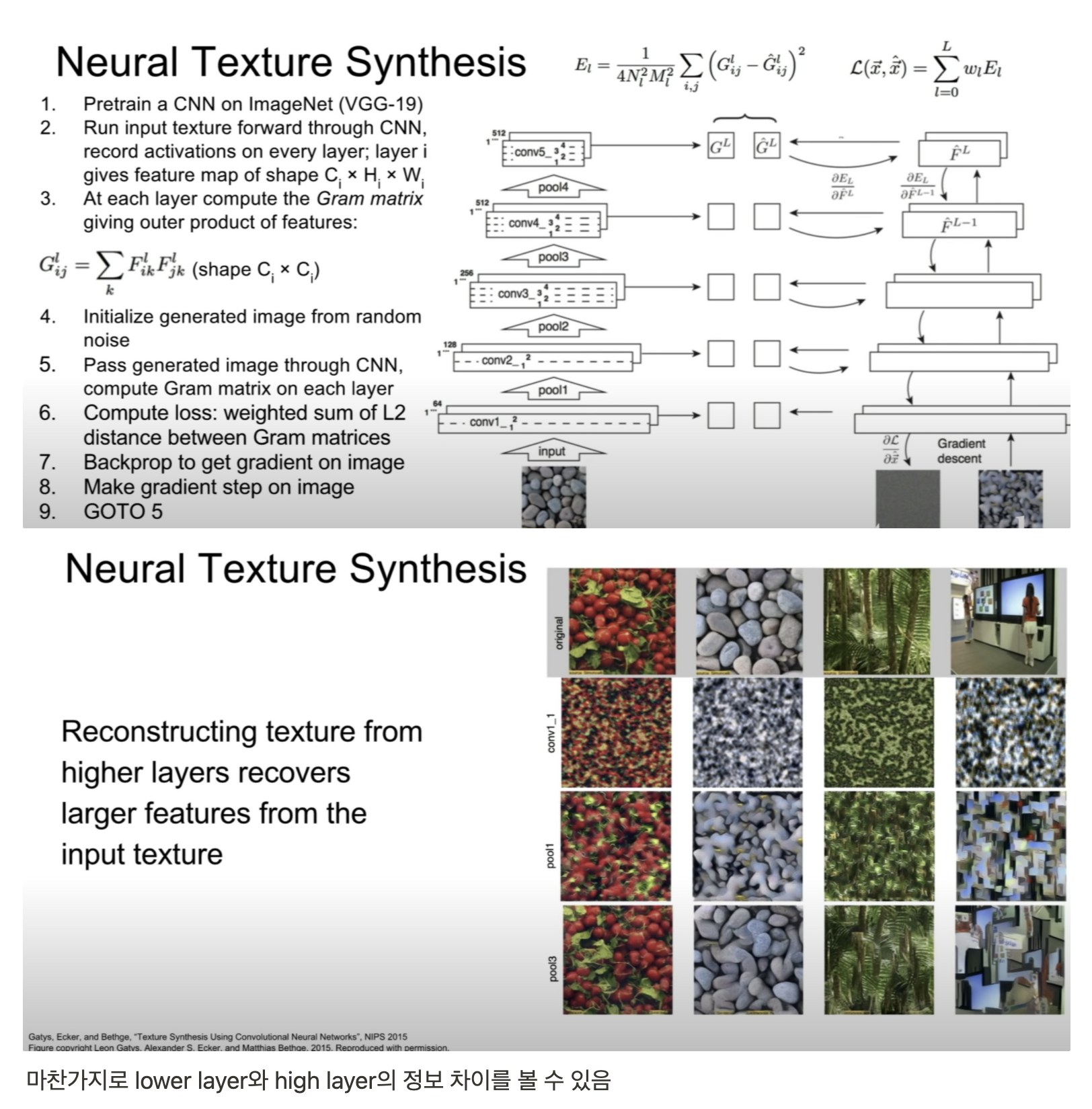
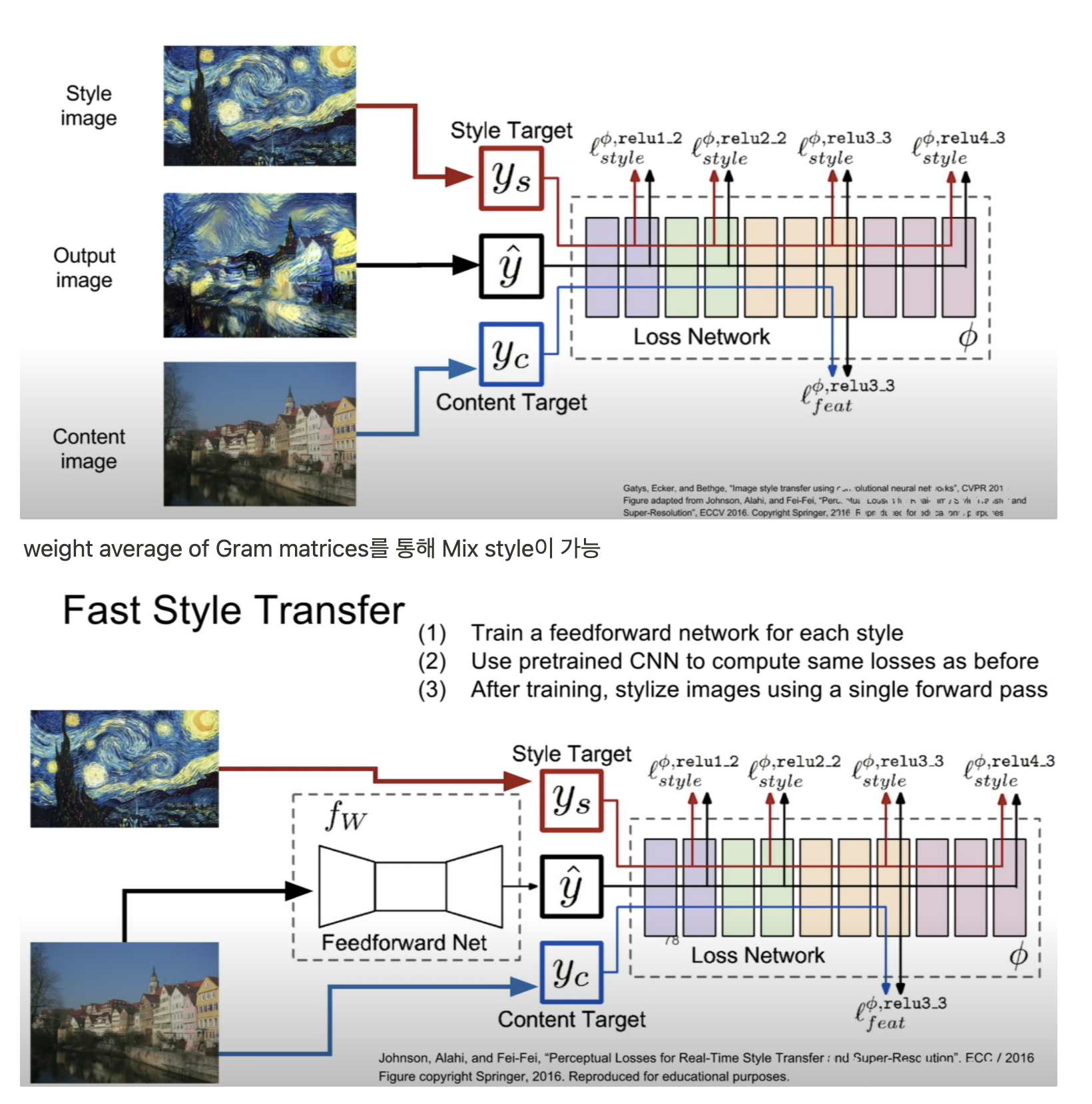
이후 AdaIN 등 Stylized method에 대한 학습은 논문과 함께 이전에 완료
Lecture 13

Unsupervised learning의 장점은 바로 cheap data, label이 필요없다. Semi-supervised learning 분야에 대한 연구가 활발하다.

pixel을 sequence로 autoregressive method로 추론하며 생성하는 모델로 pixelRNN, pixelCNN이 있다.
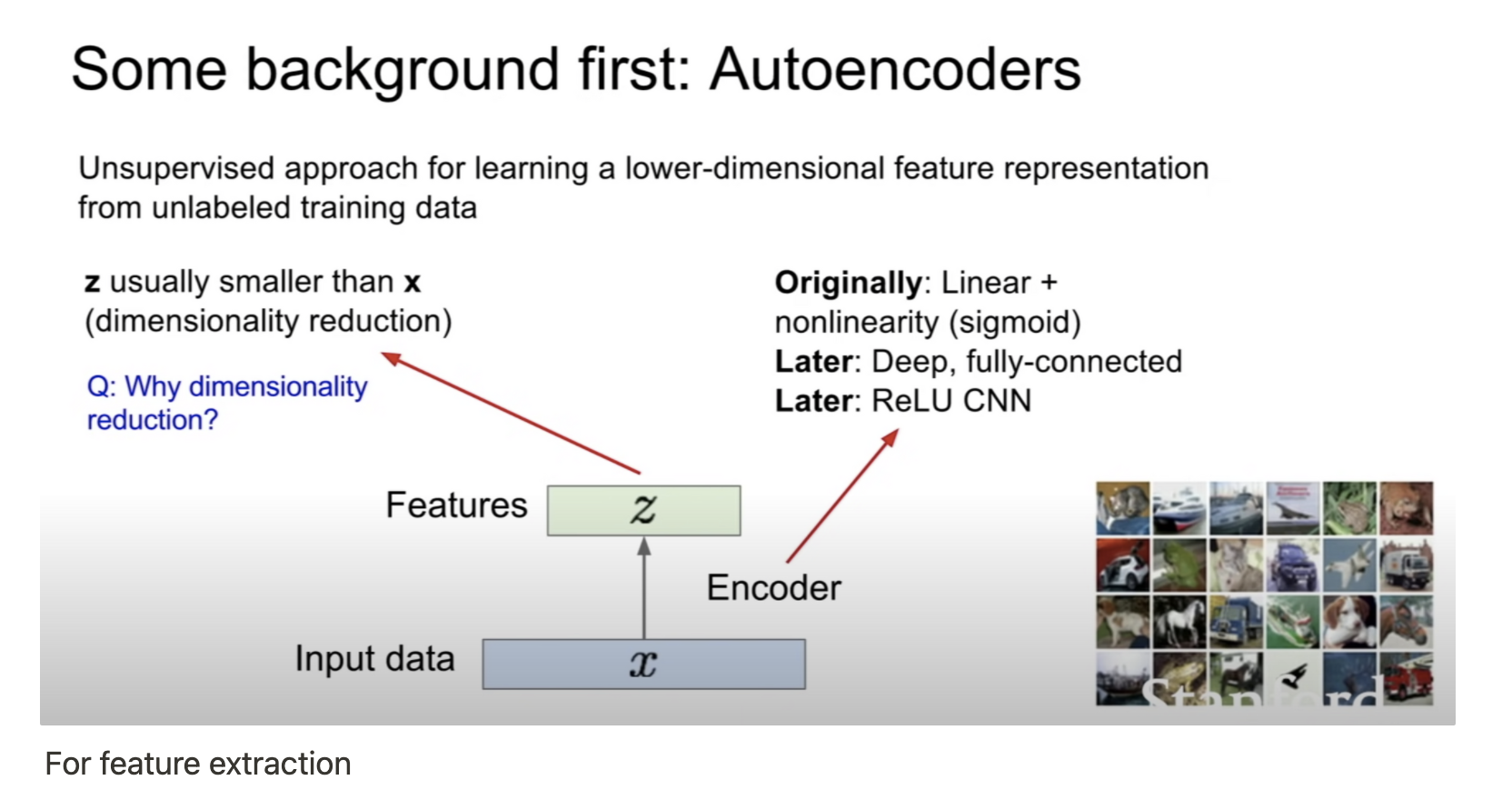
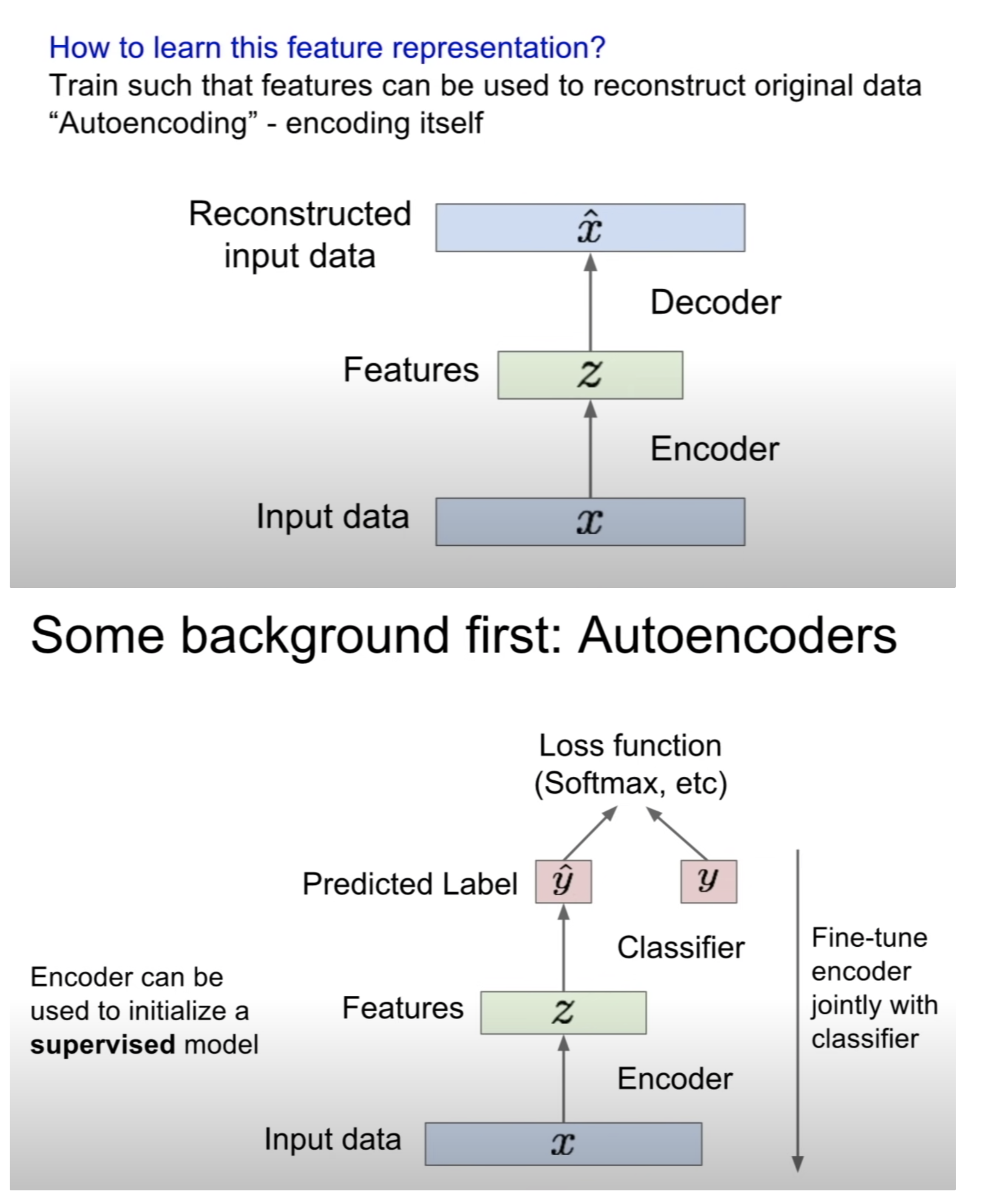
AE로 학습한 Encoder는 capture feature에 능하며 classification task에 fine-tuning 가능
VAE에 관한 내용은 세미나 발표 후 자세하게 작성 예정
'AI > Deep Learning' 카테고리의 다른 글
| Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts (0) | 2021.09.19 |
|---|---|
| Few-shot Font Generation with Localized Style Representations and Factorization (0) | 2021.09.19 |
| Few-shot Compositional Font Generation with Dual Memory (0) | 2021.09.01 |
| CS231n - Lecture 5 ~ 7 (0) | 2021.09.01 |
| CS231n - Lecture 1 ~ 4 (0) | 2021.08.21 |



