
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 모션매칭
- 폰트생성
- cv
- WBP
- Unreal Engine
- userwidget
- animation retargeting
- ddpm
- WinAPI
- GAN
- RNN
- Stat110
- Font Generation
- multimodal
- 딥러닝
- deep learning
- motion matching
- UE5
- 오블완
- Generative Model
- dl
- 생성모델
- 언리얼엔진
- Few-shot generation
- CNN
- BERT
- ue5.4
- NLP
- Diffusion
- 디퓨전모델
- Today
- Total
Deeper Learning
Few-shot Compositional Font Generation with Dual Memory 본문
ABSTRACT
- 글자가 많은 언어에 대해 새 폰트를 만드는 것은 매우 노동집약적이고 시간이 많이 든다.
- 현존하는 폰트 생성 모델은 많은 reference image를 참고하지 못하면 디테일한 스타일을 살리지 못한다.
- 조합형 글자에 대해 적은 수의 샘플을 보고 하이퀄리티의 글자를 생성해내는 DM-Font를 제시하겠다
- better quality, faithful stylization compared to SOTA font generation methods
Introduction
- GAN base image-to-image translation 방식으로 폰트를 생성하는데 전의 method는 775개의 samples이 필요했다
- 기존 방식은 pre-trained된 모델에 새로운 reference image를 사용하여 파인튜닝을 하여 새 폰트를 생성하였지만 reference image가 매우 구하기 어려운 경우 문제가 된다.
- 현재 few-shot learning은 아래 그림과 같이 높은 퀄리티의 글자를 만들어내지 못한다.

- 한국어의 11,172 글자는 68개의 초,중,종성을 디자인하고 조합하여 만들 수 있다.
- 조합에 따라 위치와 크기가 변해 rule-based method로 한계가 있다.
- 이러한 한계로 인해 조합형 글자도 각각 디자인 하고있다.
- DM-Font (Dual Memory-augmented Font Generation Network)는 weakly-supervised manner를 사용한다 ( b-box, mask를 필요로 하지 않고 각 component=초,중,종성의 label만 사용 )
- weakly-supervised 방법으로 더 효과적으로 효율적인 생성을 할 수 있었다.
- persistent memory, dynamic memory를 사용하여 효과적으로 전역적인 글자의 구조와 지역적인 component의 스타일을 잡아낸다.
- 한국어, 태국어 각각 28, 44개의 샘플로도 더 좋은 퀄리티의 글자를 생성해냈다.
Related Works
- Few-shot image-to-image translation
- image-to-image(I2I) translation은 다른 도메인 간 매핑을 학습한다.
- target domain에 맞도록 스타일을 변경시키면서 source domain의 content를 유지하는 매핑
- 보통 많은 target domain 이미지를 사용하나 few-shot translation도 최근 논문에서 소개되고 있다.
- style transfer methods는 unseen reference의 style을 original content를 유지하며 transfering
- font generation는 textures와 colors로 style이 정의되지 않고 구분 가능한 국소적인 특성에 의해 정의된다.
- 그러므로 우리의 baseline은 style transfer methods를 사용하지 않는다.
- Automatic font generation
- 다른 폰트 간 I2I translation
- Many-shot methods
- target font set의 많은 sample을 사용하여 fine-tuning
- Few-shot methods
- 많은 reference image 또는 fine-tuning을 필요로 하지 않는다.
- 현존하는 모델의 경우 전체 폰트 셋을 한 번의 forward path로 생성하기 때문에 모델의 크기가 매우 크다.
- 영어와 같이 글자의 수가 적은 언어는 생성이 쉬우나 한글이나 중국어 같은 언어는 생성이 어렵다.
- DM-Font는 SA-VAE와 달리 component 별로 feature를 처리한다.
Dual Memory-augmented Font Generation Network
- disentangle global composition information and local style
- 28개의 sample 글자로 전체 글자를 생성 가능


- Encoding phase에서 reference glyph은 초중종으로 component feature 들로 Encoded 되고 Dynamic Memory에 저장된다.
- Decoding phase에서는 target 초, 중, 종성의 index와 component feature를 fetch 한 것을 사용하여 새 glyph을 generate.Encoder
- Encoder는 pre-defined decomposition function과 3개의 Head를 이어 붙여 초중 종성의 정보로 reference glyph을 인코딩한다.
- 인코딩 된 값은 Dynamic Memory에 각각 저장된다.
- PM(persistent memory)
- component-wise learned embedding: intrinsic shape of each component
- compositionality와 같은 script의 global information을 저장
- training 이후 고정되어 변하지 않음
- DM(dynamic memory)
- 현재 주어진 reference glyph의 encoding된 초,중,종성 별 feature를 font index에 알맞은 위치에저장
- reference glyph에 따라 달라짐
- 간단하게 Encoded feature를 store and retrieve
- Reference glyph의 Encoded feature는 Encoding 때 DM에 저장된다.
- → PM은 각 초,중,종의 global information을 DM은 폰트에 따른 unique local styles을 담고있다.
- Memory Addressor
- memory_addr_function('한') = {"ㅎ","ㅏ","ㄴ"}
- pre-defined function으로 Unicode를 사용하여 초,중,종성으로 분리한다.
- Component간 관계 정보를 위해 Self-Attention block 사용

Decoder

- target glyph의 글꼴 index와 초성,중성,종성 index를 정보로 주어 glyph을 generation
- DM과 PM에 저장된 정보를 같이 활용한다.
- character를 판단하는 Discriminator, style을 판단하는 Discriminator가 BackBone을 공유한 채 branch가 나누어진 형태로 존재
- 안정적인 학습을 위해 supervised learning인 component classifier를 사용.
- compositionality를 모델이 최대한 활용할 수 있도록 하는 역할
- Generator가 global-context awareness와 local-style preservation를 할 수 있도록 Compositional Generator를 도입
- locality를 유하면서 global-context를 알기 위해 Decoder에 hourglass block 사용
- Encoder에서 Attention block을 사용하여 component 간에 relational reasoning을 가능하게 함
DM-Font는 weakly-supervised learning으로 glyph의 compositionality를 학습.
초,중,종성에 대한 b-box를 필요로 하지 않고 implicit하게 component의 label을 사용.
Font 뿐 아니라 compositionality가 존재하는 데이터를 위한 생성모델로 사용가능.
Training
- x(img), y_c(초,중,종 label), y_f(font label) 데이터를 사용한다.
- target glyph을 생성하기 위해 full component (68개의 초,중,종성 포함)이 아닌 core component(초중종성이 각각 포함된 3개의 glyph subset)을 사용
- 모델이 plausible한 이미지를 생성해낼 수 있도록 Adversarial loss를 사용

- Font Discriminator는 source font index에 대한 Discriminator, Character Discriminator는 given character를 예측.
- L1-loss: between ground truth target x and Generated glyph
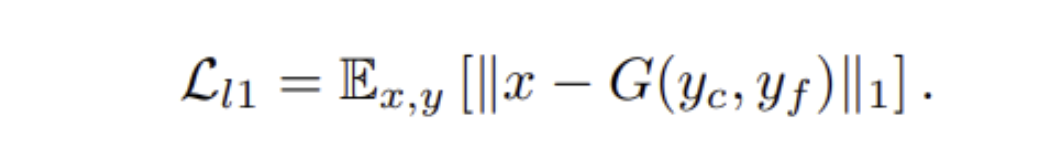
- feature matching loss
- 안정적인 학습을 위해 사용
- Discriminator의 i-th layer의 output의 L1-loss

- component-classification loss
- component의 결합으로 Glyph이 이루어지는 것을 최대한 활용하기 위해 사용
- Generated Glyph과 x를 각각 Encoder에 통과시켜 나온 값을 Component label에 대해 Cross Entropy loss를 계산하여 더한다.

- We set _λl1 = 0.1, λ_feat = 1.0, λ_cls = 0.1 for all experiments.
Experiment & Result
Dataset
- Korean-handwriting dataset
- Diversity와 Sparsity로 인해 적은 sample로 손글씨를 생성하는 것 은 매우 Challenging
- 폰트 디자이너가 refine한 86개의 손글씨 폰트를 사용
- 각 폰트는 2448개의 glyph으로 구성, 80%의 폰트와 90%의 character를 사용 나머지는 validation set으로 사용
Comparison methods and evaluation metrics
- EMD, AGIS-Net, FUNIT 등 기존 SOTA 모델과 비교
Evaluation metrics
- 생성모델의 metric 설정은 매우 어렵다. 생성모델에서 가장 좋은 metric이 무엇인지 아직도 결정할 수 없다.
- pixel-level
- SSIM (Structural Similarity index)

- MS-SSIM (Multi-Scale SSIM)
- A more advanced form of SSIM, called Multiscale SSIM (MS-SSIM)is conducted over multiple scales through a process of multiple stages of sub-sampling, reminiscent of multiscale processing in the early vision system. It has been shown to perform equally well or better than SSIM on different subjective image and video databases. [https://en.wikipedia.org/wiki/Structural_similarity]
- Human-level performance와 일치하지 않는 경우가 많다.
- perceptual-level
- Character label과 Style label을 분류하는 ResNet-50 Backbone Classifier를 2개 학습
- 모델에서 학습하면서 사용하는 Classifier와 다른 독립적인 Classifier를 사용
- context-aware, style-aware로 각각 명명함
- PD(perceptual distance), Generated Glyph과 GT Glyph의 features의 L2 Distance
- mFID(mean FID), 각 target class에 대해 FID를 평균낸 값
- human-level
- Content, Style, Total 측면에서 Glyph의 퀄리티를 설문지를 통해 측정

PD = Perceptual Distance
mFID = mean FID

Main Result
- Style-aware, PD, mFID에서 다른 모델보다 높은 점수를 받음,
- EMD는 얇은 폰트 생성 시 획을 제거하여 Content 점수가 낮았으며 FUNIT, AGIS-Net은 Style이 덜 반영되었다.
Study


Conclusion
기존 생성모델은 unseen style에 대한 생성 성능이 낮았음
weakly-supervised manner로 compositional input에서 현존 method보다 뛰어난 few-shot font generation 성공
unseen font의 Stylization은 아직 해결하여야할 과제
Extensive empirical evidence support that our framework lets the model fully utilize the compositionality so that the model can produce high-quality samples with only a few samples.
Appendix
network architecture
Encoder에 Global Context Block, Self-Attention Block 사용
Decoder에 Hourglass Block 사용
Experimental Setting
Adam
- lr = 0.0002 for gen, component classifier
- lr = 0.0008 for disc
- two time-scale update rule
Failure
Content failure는 detector 또는 user-guided font correction system으로 해결 가능
component 하나가 글꼴 내에서 여러 스타일을 가질 수 있기 때문에 발생하는 문제
Reference
[1] Hwalseok Lee et al. (2020). Few-shot Compositional Font Generation with Dual Memory. https://arxiv.org/abs/2005.10510
'AI > Deep Learning' 카테고리의 다른 글
| Few-shot Font Generation with Localized Style Representations and Factorization (0) | 2021.09.19 |
|---|---|
| CS231n - Lecture 8 ~ 13 (0) | 2021.09.11 |
| CS231n - Lecture 5 ~ 7 (0) | 2021.09.01 |
| CS231n - Lecture 1 ~ 4 (0) | 2021.08.21 |
| cGANs with Projection Discriminator (0) | 2021.08.07 |



