
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- RNN
- UE5
- WBP
- NLP
- multimodal
- 디퓨전모델
- deep learning
- cv
- motion matching
- 오블완
- Diffusion
- CNN
- 생성모델
- 폰트생성
- animation retargeting
- Stat110
- Unreal Engine
- userwidget
- Font Generation
- 딥러닝
- WinAPI
- Generative Model
- ue5.4
- 모션매칭
- ddpm
- Few-shot generation
- 언리얼엔진
- dl
- GAN
- BERT
- Today
- Total
Deeper Learning
CS231n - Lecture 5 ~ 7 본문
전체적인 내용 리뷰가 아닌 그룹 스터디 중 토론 나눴던 주제 중심으로 정리.
Lecture 5 ~ 7
Sigmoid의 문제점
- Saturated neuron kills gridients
- Not zero centered
- exp() is expensive
만약 input으로 모두 양수가 주어지면 w의 gradient는 모두 양수거나 모두 음수가 된다.
w1, w2가 x, y축을 이루는 사분면을 생각해보면 만약 4사분면에 최적의 W가 존재할 경우 w1, w2의 grad는 각각 양수, 음수로 주어져야 빠른 수렴이 가능하다.
하지만 위 상황에서 이는 불가능하여 oscillation 형태로 수렴이 느려진다.
Tanh
- zero centered
- saturated kill
Relu
- no saturated kill
- computationally efficient
- converge faster
- biologically plausible
- not zero centered
LeakyReLU
f(x) = max(-ax, x)
ELU
- f(x) = x (x>0), a(exp(x)-1) (x<=0)
- closer to zero centered
- reduce saturation problem
- robust to noise
- computing expensive
Maxout
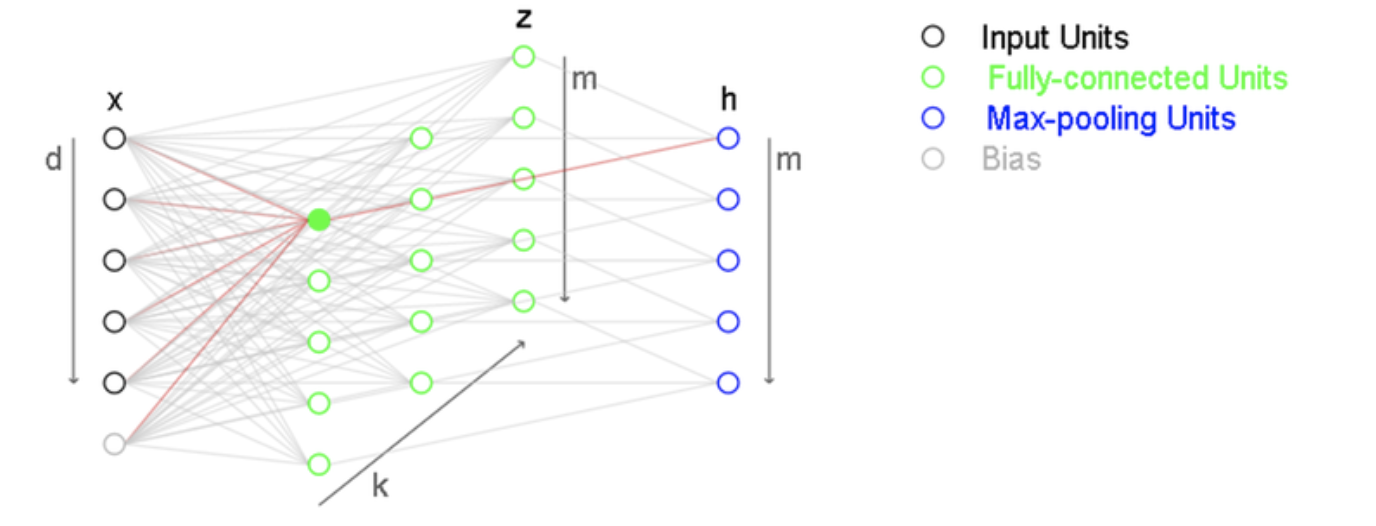
k개의 layer 층을 만들고 Max-pooling을 적용하여 같은 포지션의 node 중 가장 높은 출력값을 택한다.

위와 같은 2차 함수를 1차식으로 근사한다고 생각하면 1개의 직선 (=vanilla nn layer)로는 근사가 힘들다. 하지만 linear combination 형식의 Maxout layer를 사용하여 부분적으로 1차 식을 차용하여 더 가깝게 근사가 가능하다.
Weight Initialization
Q. What happens when w=0 initialization is used?
A. 먼저 forward propagation 부터 생각한다. W가 동일하게 0으로 설정되었으면 bias가 존재할 경우 layer output z= b의 형태가 될 것이다.
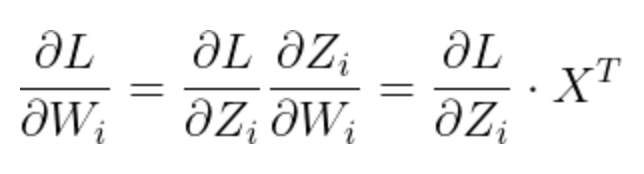
Backprop은 위 식에 의해 이루어진다. Z값은 모두 동일하기 때문에 결국 grad Z도 동일하다. X는 input으로 모든 W_i에 대해 동일하기 때문에 결국 layer의 weight가 모두 동일하게 업데이트 되어 1개의 weight를 사용하는 것과 같은 결과를 초래한다.
Q. W가 0에 가까운 매우 작은 값으로 모두 Initialization 되면 Deep Neural Network에서 어떤 문제가 발생하는가?
A. Forward propagation 측면에서 보면 먼저 ( Z = WX+b, A = act_fun(Z)) A값이 점점 작아지며 후반 layer에서 input인 A는 매우 작은 값이 된다.
Backward propagation에서 생기는 문제는 위 식을 다시 보면 알 수 있다.
각 layer의 input A의 값은 위에서 설명한 것 처럼 후기 layer로 가면서 작아진다. 후기 layer에서 dW는 A가 작아짐에 따라 같이 작아져 weight의 update가 크지 않다.

초기 layer는 위 식을 = 보면 output layer에서 부터 계산된 dZ/dX 값이 연속적으로 곱해진다. dZ/dX = W로 output layer에서부터 연속적으로 각 layer의 W (very small initialized)가 곱해지면 초기 layer의 dW도 0에 가까워진다.
전체적으로 layer의 weight가 update되지 않는 현상이 일어난다.
W가 매우 큰 절대값으로 Initialization 되면 saturated 문제가 발생. -> gradient가 0 in tanh or sigmoid
BatchNormalization
- Improve gradient flow
- higher lr을 가능하게 함
- low Initialization dependency
- regularization
- reduce saturation
BN은 scale과 shift를 담당하는 learnable parameter 감마와 베타가 있다. 감마와 베타가 없이 BN을 적용하면 항상 표준정규분포로 분포가 변하게 되는데 이는 saturation 문제를 해결한다. (tanh or sigmoid)
감마와 베타를 추가하면 모델에게 extra flexibility를 줄 수 있다. 강제로 매핑하는 것이 아닌 감마와 베타로 recover mapping이 가능한 형태로 바뀌는 것이다. 모델은 얼마나 saturation을 유발할 것 인지 직접 정할 수 있게 된다.
Test time에는 Moving average를 사용한다.
[Residual Block은 전에 작성하였던 글에 추가로 보충 예정]
Optimization

common in high dimension
SGD 단점
saddle point, local minima → zero gradient , stuck
saddle points much more common in higj dimension. (some dimension loss up, some dimension loss down)
noise가 존재할 경우 minima에 도달하는데 많은시간이 걸린다.





First-Order의 테일러 전개가 아닌 Second-Order 까지 테일러 전개를 하면?



Dropout은 Inference step에서 Train 때와 동일하게 적용할 수 없다. 같은 input에 대한 inference result가 달라지기 때문이다. 따라서 다음과 같은 trick을 사용한다.

Regularization skills: Drop connect, frational max pooling, stochastic depth
Transfer Learning은 보편적으로 사용되는 방법으로 ImageNet preatrained network를 주로 BackBone으로 설정한다.


Reference
[1] cs231n 2017, https://cs231n.github.io/
'AI > Deep Learning' 카테고리의 다른 글
| CS231n - Lecture 8 ~ 13 (0) | 2021.09.11 |
|---|---|
| Few-shot Compositional Font Generation with Dual Memory (0) | 2021.09.01 |
| CS231n - Lecture 1 ~ 4 (0) | 2021.08.21 |
| cGANs with Projection Discriminator (0) | 2021.08.07 |
| Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (AdaIN) (0) | 2021.07.27 |



