
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- animation retargeting
- 딥러닝
- Font Generation
- WBP
- 오블완
- Unreal Engine
- Generative Model
- RNN
- Few-shot generation
- 모션매칭
- WinAPI
- userwidget
- dl
- Diffusion
- multimodal
- motion matching
- ue5.4
- 언리얼엔진
- 폰트생성
- cv
- CNN
- 생성모델
- Stat110
- BERT
- UE5
- GAN
- NLP
- ddpm
- deep learning
- 디퓨전모델
- Today
- Total
Deeper Learning
Inception score (IS) 본문
Why Inception score
GAN은 생성된 결과물의 performance의 측정이 어렵다.
Generator와 Discriminator의 loss만을 보고 생성된 결과물의 performance를 측정하는 것은 정확하지 않다.
완벽한 가상의 Discriminator를 속일 수 있는 Generator가 존재한다면 측정이 가능하지만 현실적으로 불가능하다.
Generated output에 대한 performance를 측정하기 위한 metrics가 필요하고 이를 위해 고안된 여러 가지 방법 중 하나가 Inception Score.
Inception Score (IS)
Inception score(이하 IS)는 pre-trained된 inception v3 모델을 사용하기 때문에 붙여진 이름이다.
Imagenet 데이터로 학습된 inception v3 모델의 최종 output은 softmax 함수를 거친 각 label에 대한 확률 값이다.
이 값을 활용하여 GAN의 성능을 측정한다.
먼저 Fidelity와 Diversity에 대한 이해가 필요하다.
Fidelity는 생성된 이미지의 quality, 즉 얼마나 만들어진 이미지가 실제 이미지와 유사한지를 말한다.
Diversity는 생성된 이미지가 획일적이지 않고 다양한 분포를 보이는지를 의미한다.
이 2개의 지표를 활용하여 IS가 계산된다.
조건부 확률 $p(y|x)$는 Generator의 output x (생성된 이미지)가 주어졌을 때 y의 확률 값이다.
이는 생성된 이미지가 주어졌을 때 label을 맞출 확률이고 이는 얼마나 정교하게 이미지가 생성되었는지를 말하며 Fidelity로 해석이 가능하다.
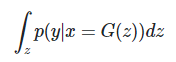
$p(y)$값은 위의 수식을 통해 구할 수 있으며 x는 z분포에서 추출된 값을 Generator에 통과시킨 값이다.
z에 대한 적분으로 marginal distribution을 구할 수 있으며 이는 $p(y)$가 된다.
Diversity는 생성해내는 이미지의 label 분포로 $p(y)$값을 Diversity라고 해석할 수 있다.
$p(y)$값이 Uniform distribution일 때 이상적이다.
Fidelity와 Diversity의 KL divergence(Kullback-Leibler divergence)의 기댓값을 지수 변환한 값이 IS가 된다.
KL divergence는 간단하게 두 분포의 정보량의 차이를 말하며 연속형 분포의 경우 다음 수식을 통해 계산된다.
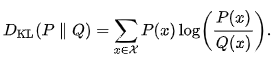
위에서 설명한 Fidelity와 Diversity를 높인다는 관점에서 $p(y|x)$에서 얻을 수 있는 정보량은 높고 $p(y)$에서 얻을 수 있는 정보량은 낮아야 한다.
즉 $D_{KL}(P ||Q)$가 큰 값을 가지도록 하여야 한다.

위 그래프에서 2번, 3번 그래프는 Fidelity가 낮아 KL devergence의 값이 중간으로 계산되었고 4번 그래프는 Diversity가 낮아 낮은 KL devergence가 나오게 되었다.

위의 수식으로 IS의 계산이 가능하다.
생성된 이미지 x를 Inception v3에 input으로 입력하여 얻은 $p(y|x)$와 $p(y)$값의 KL divergence의 평균을 자연상수 e의 지수로 한 값이 Generator의 IS value이다.
IS값이 높을수록 Generator의 성능이 좋다고 해석이 가능하다.
Pros and Cons
IS는 Generator의 성능을 어느 정도 측정할 수 있는 측정기준이 될 수 있다.
하지만 True label data를 전혀 사용하지 않고 Generator에 의해 생성된 data로만 metrics의 계산이 이루어지며 Imagenet에 의해 사전 학습되어 새로운 feature에 대한 인지가 제대로 이루어지지 않는 단점이 있다.
또 성능 문제로 FID보다 자주 쓰이지 않으며 각 label 마다 적은 수의 image가 생성될 경우 높은 IS가 기록되는 문제가 있다.
'AI > Deep Learning' 카테고리의 다른 글
| Glove (0) | 2020.12.08 |
|---|---|
| Word2Vec (0) | 2020.12.06 |
| Feature Extraction (0) | 2020.12.04 |
| Long Short-Term Memory (LSTM) (0) | 2020.12.04 |
| Gated Recurrent Units (GRU) (0) | 2020.12.03 |



