

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- userwidget
- 디퓨전모델
- multimodal
- UE5
- animation retargeting
- BERT
- WBP
- deep learning
- ddpm
- 언리얼엔진
- ue5.4
- RNN
- Diffusion
- CNN
- 언어모델
- GAN
- NLP
- cv
- 딥러닝
- 생성모델
- 폰트생성
- 모션매칭
- Stat110
- Font Generation
- Generative Model
- WinAPI
- inductive bias
- motion matching
- dl
- Few-shot generation
- Today
- Total
Deeper Learning
Word2Vec 본문
Word Embedding
Vocabulary를 사용하여 One-hot encoding을 통해 비정형 텍스트 데이터를 수치형 데이터로 전환하여 input으로 사용이 가능하다.
하지만 오직 index하나로 단어의 정보를 표현하고 특정 단어의 index를 제외하고 모두 0으로 이루어진 one-hot vector를 사용하여 생기는 데이터의 Sparsity는 통계적 모델의 성공적인 학습을 방해한다.
특정 단어의 학습이 그 단어와 유사한 단어의 학습과 전혀 다른 과정이 되기 때문에 단어 간의 유사성의 학습이 쉽지 않다.
따라서 Word Embedding이 필요하다.
Vocabulary의 size가 100,000 일 때 100,000 차원의 one-hot vector가 만들어진다. 하지만 Word Embedding을 사용하여 이를 300차원의 연속적인 실수 공간으로 매핑이 가능하다.
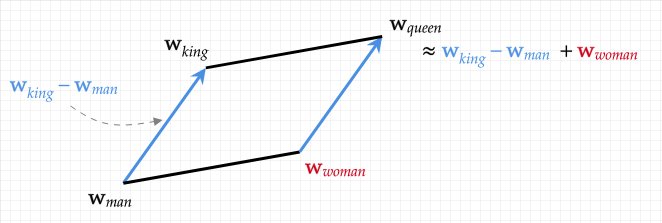
Word Embedding을 사용하면 위처럼 코사인 유사도 등의 metrics를 사용하여 king - queen = man - x에서 x가 어떤 단어인지 알 수 있다.
Word Embedding은 비지도 학습으로 output은 Vocabulary에 존재하는 단어들이 모두 지정한 차원으로 매핑된 (vocab_size, embedding_dim) shape의 matrix다.
NNLM
Neural Network Language Model은 target 단어를 설정하고 이전에 등장한 N개의 단어의 one-hot vector를 input으로 하는 모델을 사용한다.

계산량이 매우 많고 target word뒤에 등장하는 단어에 대한 정보를 전혀 사용하지 않아 성능또한 좋지 않다.
이를 개선하기 위한 여러 알고리즘이 등장하였다.
RNNLM은 NNLM에서 RNN을 사용한 모델이다.
Word2Vec
Word2Vec은 word to vector로 word embedding 자체, 또는 구현 방법, 신경망 모델 등을 가리키는 말로 용법이 다양하다.
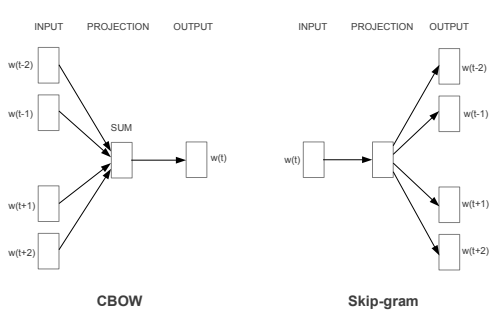
skip-gram 모델 또는 CBOW모델을 사용한다.
CBOW
CBOW (continuous bag-of-word) 모델은 주변 단어들을 보고 단어를 예측하는 지도 학습을 하는 모델을 사용한다.

Vocab size가 10,000개이고 Embedding dim이 300인 예시를 들겠다.
I want a glass of orange juice라는 문장이 있으면 'of'의 주변 단어인 glass, orange를 input으로 사용하여 output 'of'를 예측하는 모델을 학습시키는 것이다.
label인 of는 target word가 되고 glass, orange는 context word라고 한다.
context는 window size를 n으로 설정하여 target 앞과 뒤의 단어 n개를 context로 사용하거나 target 앞의 4개의 단어를 context로 사용하는 등 변형이 가능하다.
Embedding matrix W는 (10,000, 300)의 shape로 초기화되고, hidden layer에서 output layer 사이의 Weight W'은 (300,10,000)의 shape로 초기화된다.
output layer는 softmax 함수를 사용하여 Vocab size인 10,000d의 벡터로 변환된다.
모델의 학습 결과 Weight matrix W에 단어의 출현 패턴을 파악한 벡터가 학습이 된다.
Loss는 다중 분류 문제이기 때문에 Cross entropy Error를 사용한다.
W와 W` 둘 다 단어의 출현 패턴의 학습이 되어있지만 많은 연구에서 주로 W (input layer와 hidden layer사이의 가중치)를 Embedding matrix로 채택한다.
Skip-gram

Skip-gram 모델에서는 반대로 중앙의 target에서 Context를 예측하는 모델이다.
Loss는 true label인 one-hot encoding 된 context words와 output layer의 context의 개수만큼 생성된 같은 벡터와의 Cross-entropy error의 합이다. ($y_{aj} = y_{bj}$)
보통 Skip-gram의 모델의 성능이 더 뛰어난데 이는 skip-gram의 모델이 더욱 어려운 과제를 학습하기 때문이다.
비어있는 한 개의 단어의 예측보다 한 단어에서 다른 맥락 단어를 예측하는 것이 더 어렵고 학습량 또한 많다.
Improvement
Vocabulary의 size는 corpus의 크기가 큰 데이터의 경우 매우 크다.
따라서 계산에 오랜 시간이 걸리게 되고 이를 개선하기 위한 방법이 있다.
먼저 모델에서 input값은 one-hot vector로 이를 Weight matrix와 내적 하는 것은 (vocab_size - 1) 개의 불필요한 0과 W의 원소의 곱을 수행한다.
대신 Weight matrix에서 행을 추출하여 이를 해결할 수 있다.

Softmax의 또한 Vocab size가 커지면 계산량이 매우 많아진다.
이를 해결하기 위한 방법으로 Negative Sampling이 있다.
Negative Sampling
Negative Sampling은 Softmax로 인한 계산량을 줄이기 위해 고안된 방법이다.
하나의 단어를 예측하고 나서 모든 단어에 해당하는 W가 update 되는데 이는 비효율 적이기 때문이다.
따라서 negative(오답)을 모두 update하지 않고 일정 개수 k만큼 sampling 하는 것이 Negative Sampling이다.
다중 분류 문제를 이진 분류로 변환하여 이를 해결할 수 있다.
Sigmoid로 Softmax를 대체하고 정답의 경우 label을 1, 오답일 경우 label을 0으로 한다.
정답 1개와 오답 k개 (논문에서 큰 데이터셋에서 k는 2~5, 작은 데이터셋에서 5~20으로 제안)를 샘플링한다.

hidden layer의 activation을 각각 k개의 동일한 W`와 내적 하고 결괏값을 Sigmoid 함수를 통해 0~1의 값으로 만들고 threshold에 따른 이진 분류를 하여 binary cross entropy error의 합을 Loss로 정한다.
샘플링 기법은 정답의 경우 기존과 같다. 오답의 샘플링의 경우 전체 corpus의 확률분포에서 추출이 가능하다.
이 방법의 경우 자주 등장하는 단어인 the, a가 많이 추출되고 희소한 단어는 거의 추출이 되지 않는 문제점이 있다.
uniform distribution에서 추출을 하면 많이 사용되는 단어의 학습이 한 번 등장한 단어와 같은 횟수 학습되는 형평성에 문제가 있다.
따라서 단어의 샘플링 확률은 논문에서 제시된 다음과 같은 수식에 따른다.

$P(w_{i})$는 단어가 선택될 확률이며 $f(w)$는 단어 w가 corpus에 등장하는 횟수이다.
예를 들어 단어 a가 2번, 단어 b가 1번 등장한 corpus가 있다면 두 단어의 샘플링 확률은 uniform distribution에서 샘플링하면 (0.5, 0.5), 등장 횟수에 따른 샘플링은 (0.6666..., 0.3333...), 위 수식을 사용하면 (0.627, 0.373)가 나온다.
Hierarchical Softmax

위와 같이 class가 2개인 다중 분류를 여러 번 시행하는 tree구조를 사용하여 아래 terminal node까지 도달할 때까지 edge의 확률 값을 곱하여 각 단어별 output을 구한다.
밑이 2인 log의 시간 복잡도를 가지며 단어의 등장 빈도에 따라 tree의 균형은 맞지 않을 수 있다.
Reference
Long Chen et al. (2018). Improving Negative Sampling for Word Representation using Self-embedded Features
Tomas Mikolov et al. (2013). Efficient Estimation of Word Representations in Vector Space
'AI > Deep Learning' 카테고리의 다른 글
| Beam Search (0) | 2020.12.24 |
|---|---|
| Glove (0) | 2020.12.08 |
| Inception score (IS) (0) | 2020.12.04 |
| Feature Extraction (0) | 2020.12.04 |
| Long Short-Term Memory (LSTM) (0) | 2020.12.04 |



