
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Stat110
- 폰트생성
- NLP
- WinAPI
- 언리얼엔진
- BERT
- Generative Model
- ue5.4
- 디퓨전모델
- CNN
- UE5
- Font Generation
- multimodal
- WBP
- ddpm
- 모션매칭
- Diffusion
- animation retargeting
- Few-shot generation
- RNN
- GAN
- 딥러닝
- Unreal Engine
- inductive bias
- 생성모델
- cv
- deep learning
- userwidget
- motion matching
- dl
- Today
- Total
Deeper Learning
Full Stack Deep Learning - Lecture 4 본문
Lecture 4
Transfer Learning
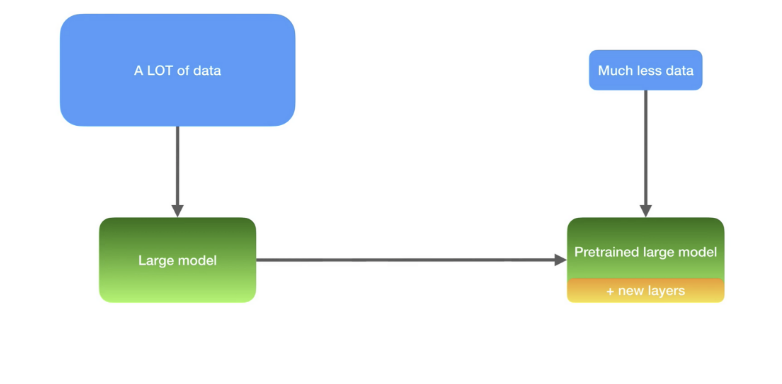
10k labeled 데이터로 classifier 학습.
이미지넷처럼 ResNet-50을 사용하고 싶으나 모델이 너무 커 작은 데이터에 쉽게 오버피팅
ImageNet에서 pretrained된 ResNet-50을 load하고 10k data로 fine-tuning
→ 성능 향상
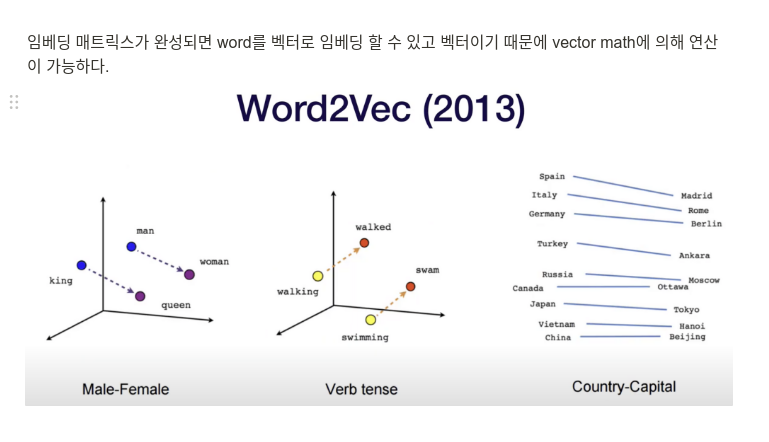
Language Model
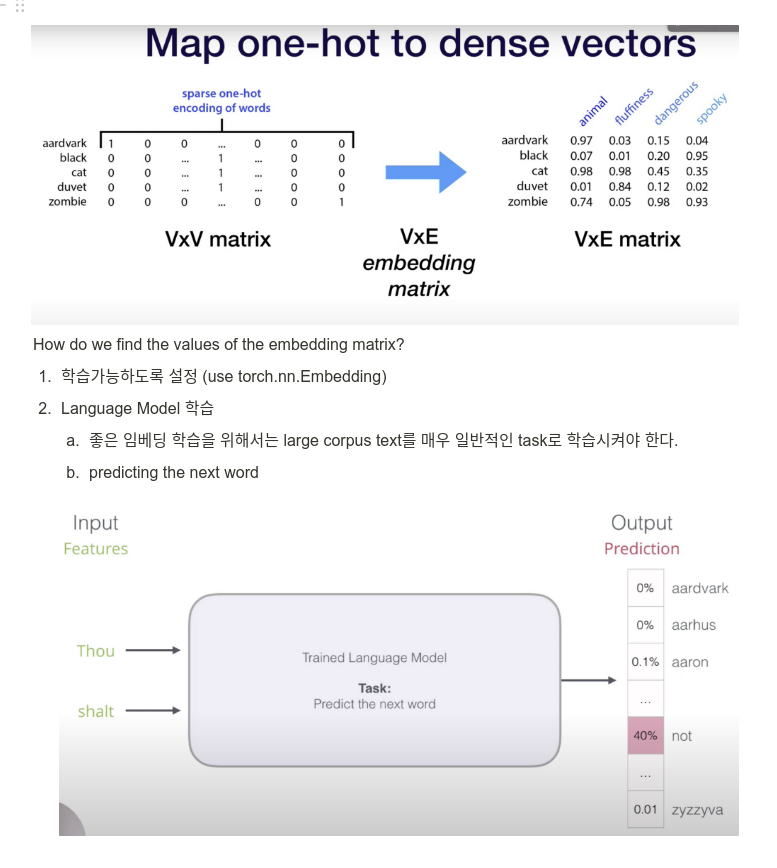
need to converting word to vectors
- one hot encoding
- Scaled poorly with vocab size
- Very high-dimensional sparse vectors → NN operations work poorly
- Violates what we know about word similarity (ex. dist(run, running), dist(run, poetry))
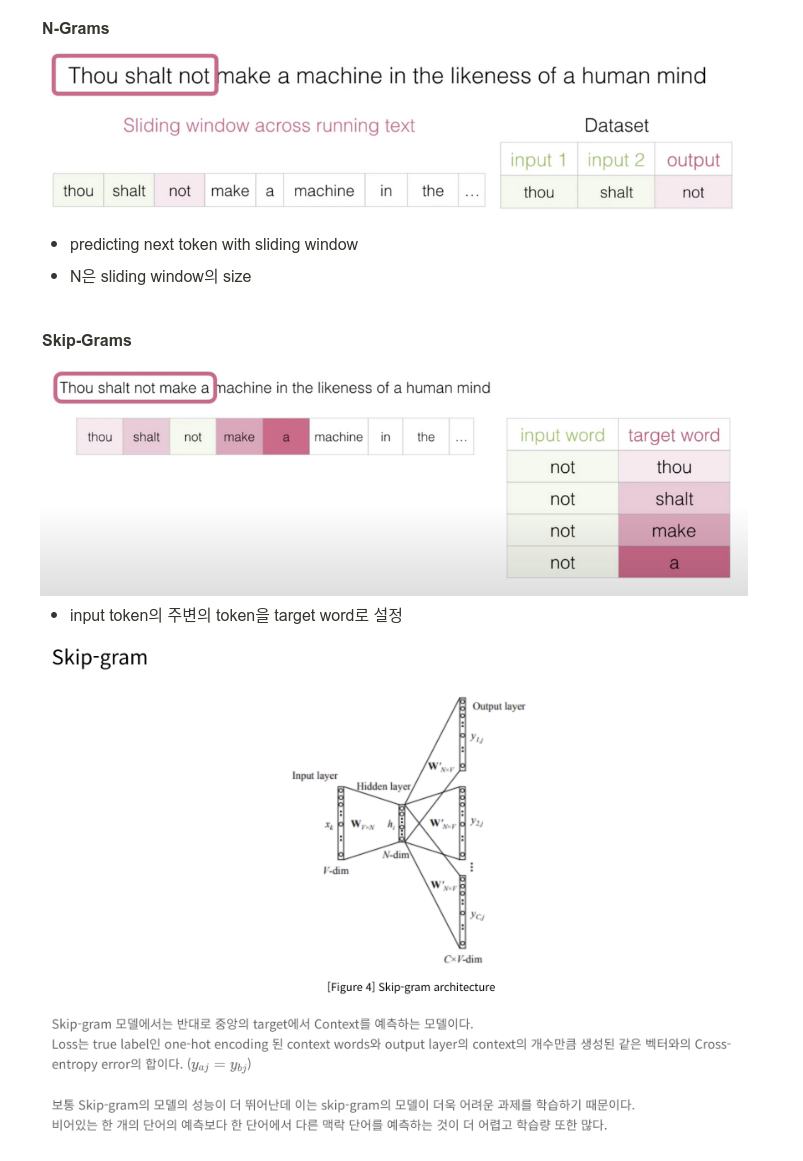
Problem: Too Slow
총 10만개의 vocab이 있다면 10만개의 class에 대한 multi-class classify.
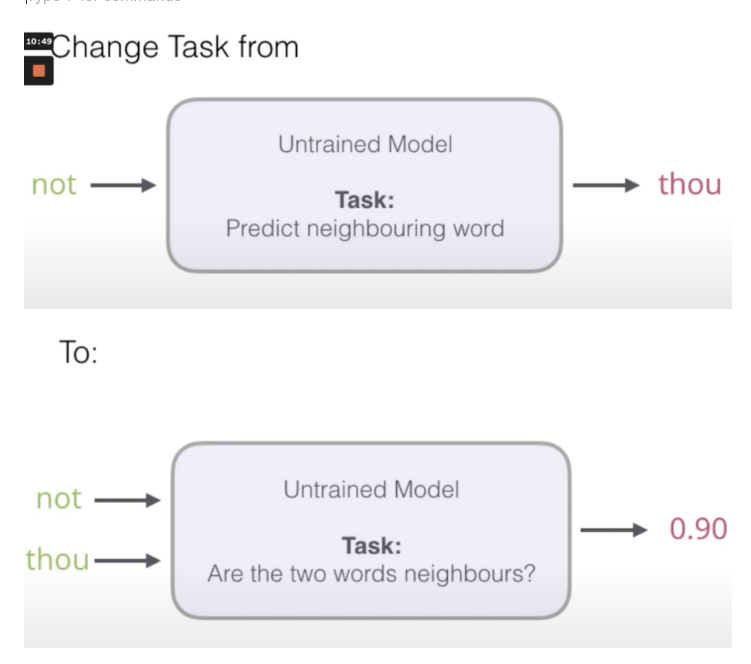
training speed up을 위한 trick으로 Binary Classification을 사용
[주변 단어 예측해라] → [두 단어가 인접해있는가?]로 task를 변경
Glove
word2vec의 단점을 지적.
학습이 가능한 데이터 페어가 window에 의해 한정되기 때문에 말뭉치 전체의 정보 (co-occurrence)를 담기 어렵다.
임베딩된 두 단어 벡터의 내적이 말뭉치 전체에서의 동시 등장확률 로그값이 되도록 목적함수를 정의.
→ 임베딩된 단어벡터 간 유사도를 측정을 수월하게, 말뭉치 전체의 통계정보를 활용하자.\
w는 Word2vec에서와 마찬가지로 2개의 생성되는 input layer와 hidden layer사이의 weight matrix이다.
w'은 hidden layer와 output layer사이의 matrix로 w의 전치 행렬과 같은 형태를 가진다.
임베딩 된 벡터로 Co-occurrence prob ratio를 나타내기 위해 위와 같이 식을 보기 편하게 바꾸었다.
마지막에 w_i − w_j가 함수 F의 input으로 들어간 이유는 두 단어 사이의 비율은 임베딩된 벡터 공간에서 다음과 같이 두 벡터의 차를 활용하여 나타내도록 유도하기 위함이다.
Glove의 아이디어는 Word2vec과 같은 방식의 local window를 사용한 Embedding에 corpus 전체의 global한 단어의 분포 정보를 추가하자는 것이다.

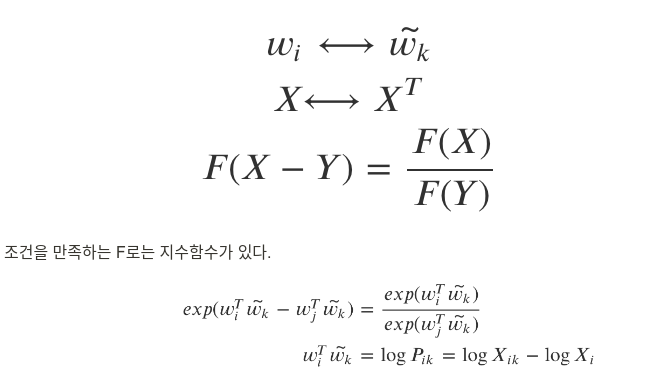

Reference
[1] https://www.youtube.com/watch?v=lOYT3-UbUvw&list=PL1T8fO7ArWlcWg04OgNiJy91PywMKT2lv&index=9
'AI > Deep Learning' 카테고리의 다른 글
| Adaptive Convolutional Kernels (0) | 2021.11.05 |
|---|---|
| Full Stack Deep Learning Lecture 5 ~ 7 (0) | 2021.10.30 |
| U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation (0) | 2021.10.27 |
| CBAM: Convolution Block Attention Module (0) | 2021.10.24 |
| Squeeze-and-Excitation Networks (SE-Net) (0) | 2021.10.14 |



