

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 디퓨전모델
- ue5.4
- Unreal Engine
- 오블완
- UE5
- 폰트생성
- GAN
- CNN
- 생성모델
- BERT
- userwidget
- RNN
- WinAPI
- 딥러닝
- deep learning
- 언리얼엔진
- Generative Model
- WBP
- dl
- Stat110
- ddpm
- motion matching
- animation retargeting
- Few-shot generation
- 모션매칭
- Diffusion
- NLP
- cv
- multimodal
- Font Generation
Archives
- Today
- Total
Deeper Learning
Full Stack Deep Learning Lecture 5 ~ 7 본문

Lecture 5
Setting up ML Projects
85% of AI projects fail


Prioritizing projects
ML project의 feasibility
Data availability
- stable?
- hard to acquire?
- expensive labeling?
- how much data is needed?
- security requirements?
Accuracy requirement
- how costly are wrong pred?
- how frequently does the system need to be right to be useful?
- ethical implications
Problem difficulty
- is the problem well-defined?
- good published work on similar problems?
- compute requirements
- Can a Human do it?


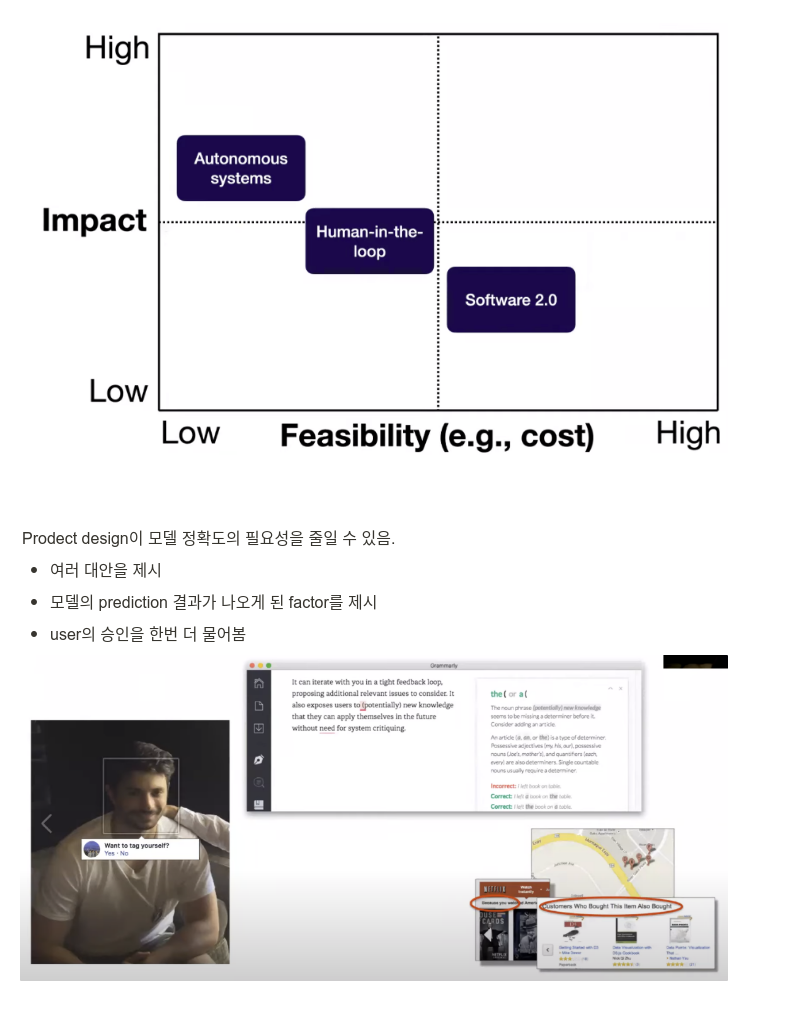
Apple의 ML product 디자인 가이드
- What role does ML play in your app?
- Critical or complementary?
- Private or public?
- Proactive or retroactive?
- Visible or invisible?
- Dynamic or static?
- How can you learn from your users?
- Explicit feedback
- Implicit feedback
- Calibration during setup
- Corrections

How to combine metrics
- Simple weighted avg
- Threshold n-1 metrics, evaluate the nth
Thresholding metrics
- which metrics?
- 도메인에 따라 결정,
- 모델의 선택에 가장 덜 민감한 metrics
- 얻고자 하는 결과에 가장 근접한 metrics
- threshold values
- 도메인에 따라 결정
- baseline의 성능에 따라 조정
- 현재 metric이 얼마나 중요한 지를 고려
mAP (mean Average Precision)
AP: Recall - Precision 그래프의 하단 면적


Lecture 6

- Use python
- scientific and data computing libraries
Editors
- Vim
- Emacs
- Jupyter
- Great as first draft
- hard to scale up
- Hart to version
- not good for distributed task, long task
- VS Code
- peek docu
- bulit-in git tolls
- remote
-
- terminal
- notebook port forwardin
- PyCharm
Streamlit
- python code → visualization

Framework
Why?
- auto-differentation and CUDA are a lot of work


Lecture 7







남은 강의들은 노션에 정리 예정.
Reference
[1] Full Stack Deep Learning 5~7
https://www.youtube.com/playlist?list=PL1T8fO7ArWlcWg04OgNiJy91PywMKT2lv
'AI > Deep Learning' 카테고리의 다른 글
| MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (0) | 2021.11.06 |
|---|---|
| Adaptive Convolutional Kernels (0) | 2021.11.05 |
| Full Stack Deep Learning - Lecture 4 (0) | 2021.10.30 |
| U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation (0) | 2021.10.27 |
| CBAM: Convolution Block Attention Module (0) | 2021.10.24 |
'AI/Deep Learning' Related Articles
more




Comments