

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- Few-shot generation
- multimodal
- deep learning
- ue5.4
- cv
- RNN
- userwidget
- WBP
- Stat110
- Generative Model
- CNN
- 생성모델
- 오블완
- 모션매칭
- 디퓨전모델
- Font Generation
- 언리얼엔진
- Unreal Engine
- motion matching
- 딥러닝
- 폰트생성
- GAN
- WinAPI
- dl
- NLP
- UE5
- ddpm
- animation retargeting
- Diffusion
- BERT
Archives
- Today
- Total
Deeper Learning
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 본문
AI/Deep Learning
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Dlaiml 2021. 11. 6. 00:27Abstract
- mobile, embedded vision application을 위한 depth-wise seperable convolutions을 활용한 경량화 모델 MobileNets을 제시
- latency와 accuracy의 trade off를 조정하는 2개의 global hyperparameters 제시
- MobileNets을 다른 모델과 비교하며 여러 실험을 통해 효율성을 검증하였음
- 다양한 task에 적용 가능
1. Introduction
- limited platform에서 빠르게 동작하여야 하는 real-word의 application이 다수 존재 (Robotics, self-driving)
- 2개의 hyper-parameters를 사용하여 모바일 및 embedded vision application에서 design requirements에 맞는 low latency, small efficient network architecture를 제시
2. Prior Work
- 작고 효율적인 neural network에 대한 연구가 최근(2017)에 많이 진행되었다.
- MobileNets 논문은 모델 개발자가 resource 제한(latency, size)에 따른 small network를 선택할 수 있도록 class of network architectures을 제시
- 많은 논문들이 size에 최적화에 집중하지만 MobileNet은 latency도 고려
- MobileNet의 주요 모듈은 depthwise separable convolution
- reduced computation networks: Xception, Squeezenet, structured transform networks, deep fried convnets
- shrinking, factorizing, compressing pretrained networks, distillation, low bit networks 등의 접근방식도 있다
3. MobileNet Architecture
- core layer인 depthwise separable filters, shrinking hyperparamters인 width multiplier & resolution multiplier
3.1. Depthwise Separable Convolution
- factorized convolution
- standard convolution → depthwise convolution & 1x1 convolution(pointwise convolution)
- MobileNet의 depthwise convolution은 각 input 채널마다 하나의 filter를 사용

- Input size가 D * D * M이고 output size가 D * D * N이고 Kernel의 size가 (F, F) 일 때 Convolution 별 연산량
- Standard Convolution: F x F x M x N x D x D
- Depthwise Convolution (only for N == M ) : F x F x M x D x D
- Depthwise Seperable Convolution: F x F x M x D x D + M x N x D x D
- Standard Convolution과 Depthwise Seperable Convolution의 연산량을 비교하면 아래와 같으며 3x3 depthwise seperable convolution을 사용하는 MobileNet에서 8~9배 연산량이 적다

3.2. Network Structure and Training

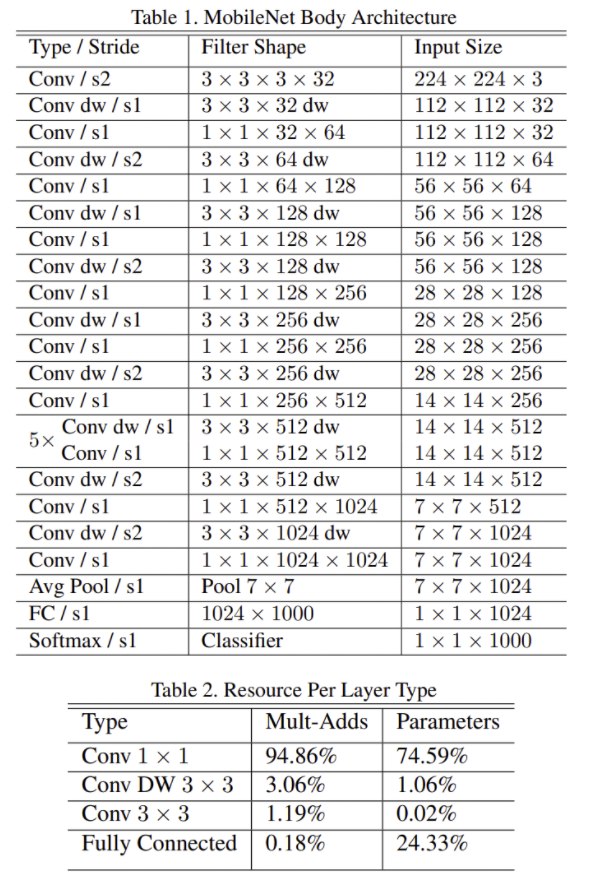
- 대부분의 연산과 parameters가 1x1 Conv에 있음
- 1x1 conv 연산은 highly optimized general matrix multiply function인 GEMM에 의해 framework에서 이루어진다.
- parameter가 적은 depthwise filter에 weight decay를 거의 적용하지 않는 것이 더 좋은 성능을 보였다
3.3. Width Multiplier: Thinner Models
- 이미 MobileNet은 충분히 작고 레이턴시가 적은 모델이지만 디바이스에 따라 더 작고 빠른 모델이 필요할 수 있다
- width multiplier $\alpha$ 를 사용하여 각 layer를 uniform 하게 thin 하게 만들 수 있다
- $\alpha$ 가 1인 경우 baseline MobileNet, 0.75, 0.25, 0.5 등일 경우 reduced MobileNets
- input channel M은 $\alpha$M이 되고 output channel N은 $\alpha N$ 이 된다.

- 연산량은 위와 같이 감소하며 quadratic 하게 대략 $\alpha^2$ 만큼 줄어든다.
3.4. Resolution Multiplier: Reduced Representation
- $\rho$ 는 Resolution Multiplier로 input image와 internal representation의 resolution을 줄인다
- $\rho$ 는 0~1의 값으로 input resolution이 224, 192, 160, 128로 $\rho$ 에 의해 바뀐다.
- $\alpha$ 와 마찬가지로 $\rho$ 도 computational cost를 대략 $\rho^2$ 만큼 줄인다.

4. Experiments
- Table 4
- 훨씬 적은 parameter와 계산량으로도 비슷한 성능
- Table 5
- depth를 줄인 shallow 모델과 width를 줄인 thinner 모델의 성능을 비교, thinner 모델이 더 좋은 성능을 보임
- Table 6, 7
- $\alpha$ 가 매우 작아지기(0.25) 전까지는 smooth 하게 성능이 조금씩 하락
- $\rho$ 도 마찬가지로 smooth 하게 성능 하락
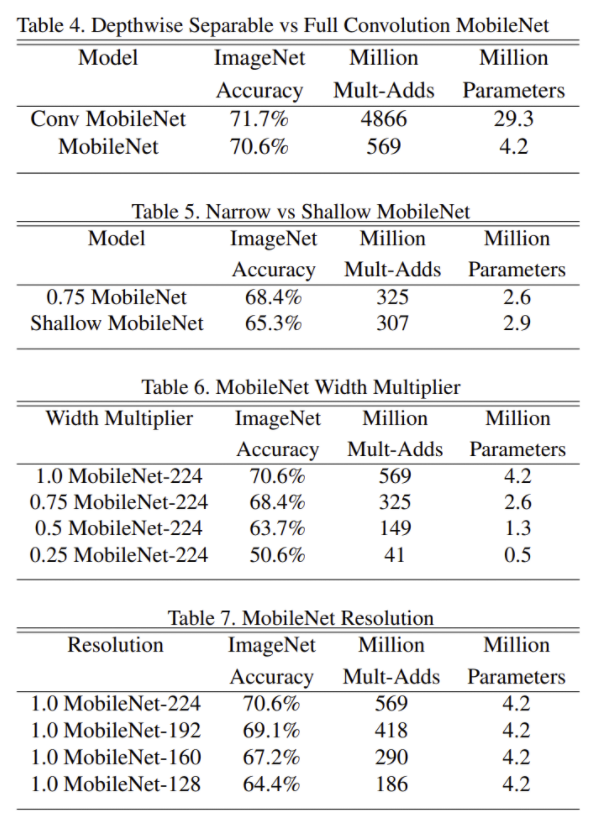
- Figure 4,5
- 계산량과 parameters 수에 따른 ImageNet에서 정확도 비교
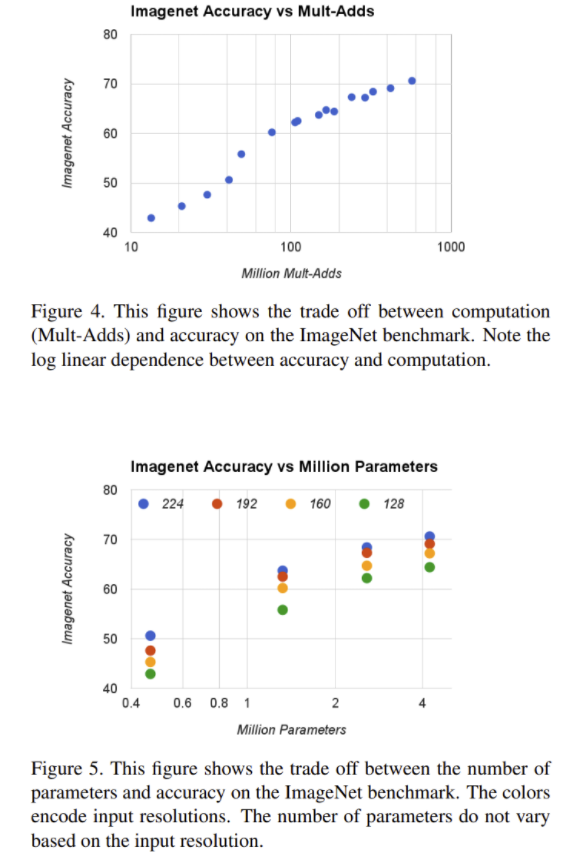
- Table 8~10,
- 다른 모델과의 성능 비교
- GoogleNet, VGG보다 좋은 성능 Inception V3보다 다소 떨어지는 top-1 acc
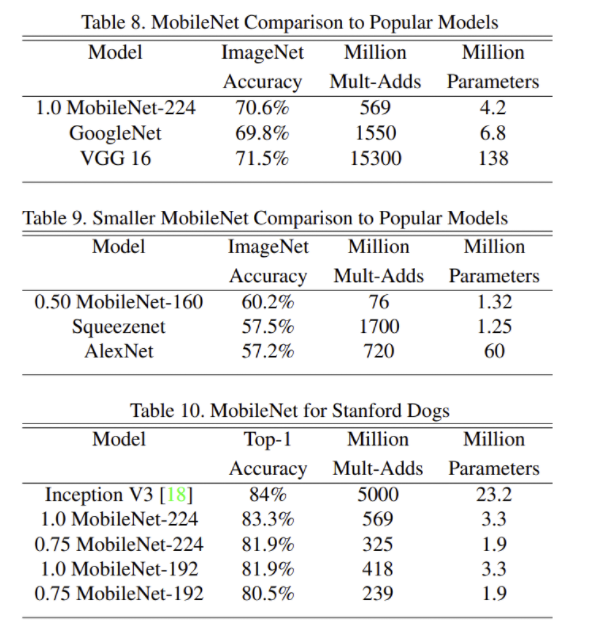
- 여러 Task에서 성능
- MobileNet을 사용한 모델의 크기는 매우 작으며, 성능은 큰 차이가 없음
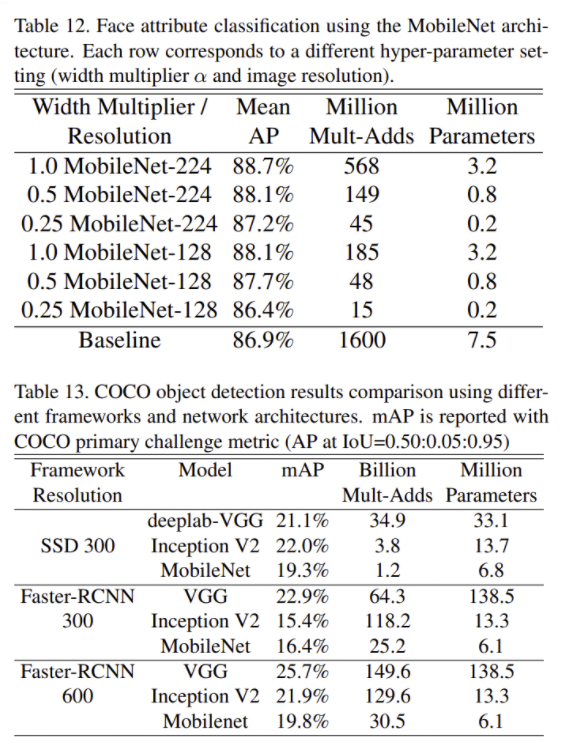
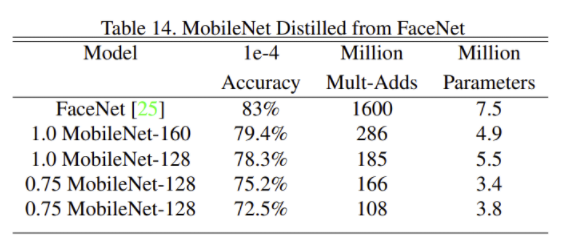
5. Conclusion
- depthwise separable convolution을 base로 하는 가볍고 빠른 MobileNet을 제시
- width, resolution multiplier를 사용하여 모델의 정확도와 속도 & latency의 trade off를 조절할 수 있음
- 다른 유명 모델에 비해 params의 수, 연산량이 매우 적음에도 불구하고 비슷한 성능을 보임
- 다양한 task에서도 효과적으로 작동함을 보임
정리 & 후기
- depthwise seperable convolution (depthwise convolution + pointwise convolution)으로 standard convolution을 대체하여 효과적으로 연산량과 params 수를 줄임
- 기존 모델에 비해 성능도 크게 떨어지지 않아 임베디드 디바이스에서도 사용할 수 있는 모델
- depth, resolution, width를 줄이지 않으면서 convolution 연산 자체를 개선하여 경량화를 성공
- v2에서 추가로 channel axis의 연산량을 Bottleneck Residual Block을 사용하여 개선
Reference
Andrew G. Howard et al. (2017). MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
'AI > Deep Learning' 카테고리의 다른 글
| You Only Look Once: Unified, Real-Time Object Detection (0) | 2021.11.30 |
|---|---|
| Pixel-Adaptive Convolutional Neural Networks (0) | 2021.11.16 |
| Adaptive Convolutional Kernels (0) | 2021.11.05 |
| Full Stack Deep Learning Lecture 5 ~ 7 (0) | 2021.10.30 |
| Full Stack Deep Learning - Lecture 4 (0) | 2021.10.30 |
'AI/Deep Learning' Related Articles
more




Comments