

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- ddpm
- cv
- ue5.4
- 모션매칭
- 디퓨전모델
- Diffusion
- BERT
- animation retargeting
- CNN
- 폰트생성
- Few-shot generation
- NLP
- Stat110
- UE5
- RNN
- inductive bias
- userwidget
- 딥러닝
- motion matching
- dl
- multimodal
- 언어모델
- WinAPI
- WBP
- Font Generation
- Generative Model
- GAN
- deep learning
- 생성모델
- 언리얼엔진
- Today
- Total
Deeper Learning
Semantic Segmentation 본문
Semantic segmentation
Semantic segmentation은 이미지의 픽셀 별로 label을 부여하는 task로 각 instance 별로 구분은 하지 않는다.

Fully Convolutional Network (FCN)
FCN은 Semantic Segmentation을 수행 가능한 네트워크 구조 중 하나로 Image Classification을 위한 네트워크의 아키텍처에서 Fully Connected Layer를 Fully Connected Layer로 대체한 형태의 아키텍처를 가지는 모델이다.
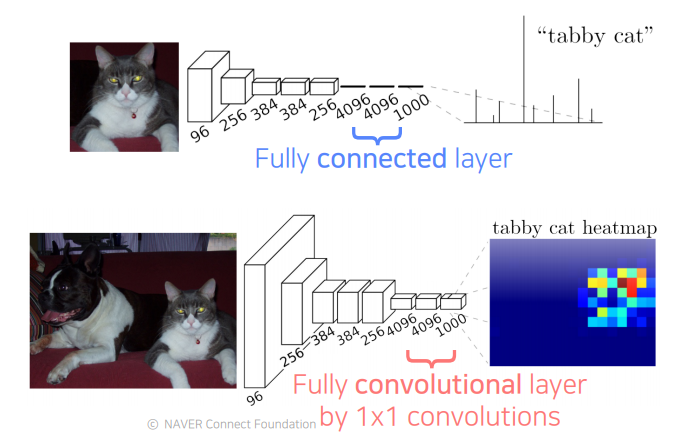

1x1 convolution layer를 사용하여 activation map의 차원을 조절하며 마지막에는 class 갯수와 동일한 차원의 activation map이 나오게 된다. width와 height의 경우 1x1 convolution layer를 사용하여 그대로 유지된다.
flatten layer를 사용하지 않기 때문에 각 pixel이 receptive field의 위치 정보를 그대로 가지고 있기 때문에 이를 semantic segmentation을 달성하는 데 사용할 수 있다.
하지만 네트워크 구조를 도식화한 그림에서 볼 수 있듯이 input image가 layer를 통과하면서 크기가 줄어들어 마지막 output이 크기가 작아지는 low-resolution 문제가 발생한다.
Upsampling을 사용하여 이를 본래 이미지의 width와 height와 같게 크기를 맞출 수 있다.
Upsampling 방법에 대해 알아보겠다.
Upsampling
upsampling은 small activation map을 input image의 크기와 동일하게 바꿔준다.
Unpooling

unpooling은 pooling을 역으로 진행하는 것과 같다.
pooling layer를 통과할 때 대표값으로 선정된 index를 저장하고 unpooling layer를 통과할 때 다시 저장된 index에 맞게 값을 배치해준다.
위의 그림을 보면 이해가 쉽다.
Transposed Convolution
Transposed Convolution 은 Convolution의 방향을 바꾼 것과 비슷하게 동작한다.


위의 2개의 그림을 보면 이해가 쉬운데 input값이 filter의 값과 곱해져 각 위치의 output값이 계산된다. convolution layer에서 input에서 하나의 pixel이 여러 번 filter에 의해 계산이 되는 것처럼 Transposed convolution layer에서는 input이 아닌 output이 겹쳐서 나오게 되고 이는 더하여 계산한다. (위 그림에서 az+bx)


output에서 특정 pixel은 합하여 계산된 값을 가지기 때문에 위와 같이 kernel size=3, stride=2 인 Trasposed Convolution이 이루어질 때 4개의 값이 합쳐진 짙은 검은색 부분, 2번 값이 합쳐진 회색 부분과 같이 마치 Checkerboard모양으로 output이 나오게 된다.
이는 첫 번째 그림처럼 checkerboard 패턴을 만들어내어 output의 품질을 낮추게 된다.

학습가능한 covolution layer와 NN, Bilinear를 통한 보간을 함께 사용한 resize convolution을 통해 checkerboard문제를 해결할 수 있다.
FCN skip connection
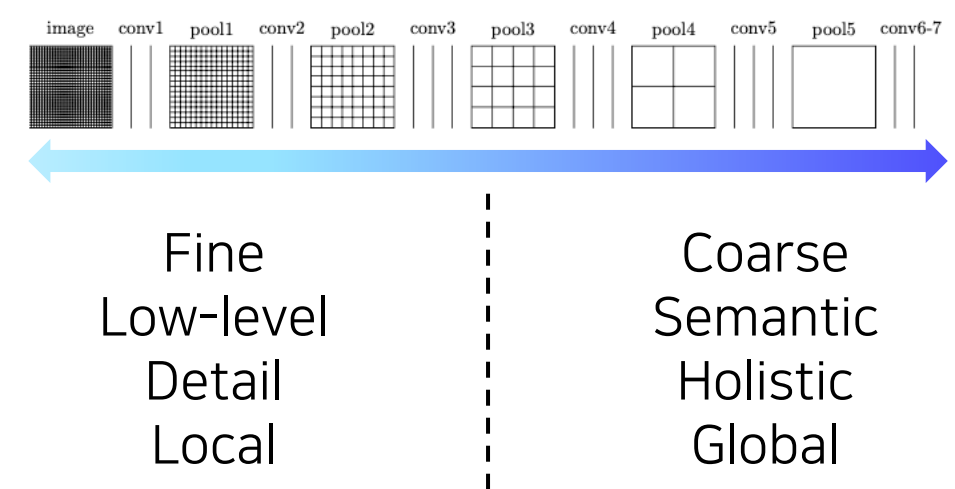
초기의 filter는 edge, color와 같은 단순한 low-level feature를 포착하도록 학습되며 후반 layer의 filter는 전체적인 특성, 의미 있는 특징을 포착하도록 학습된다.
lower-level의 특성을 함께 사용하기 위해 skip connection을 사용하여 lower layer의 activation map을 output과 더해준다.

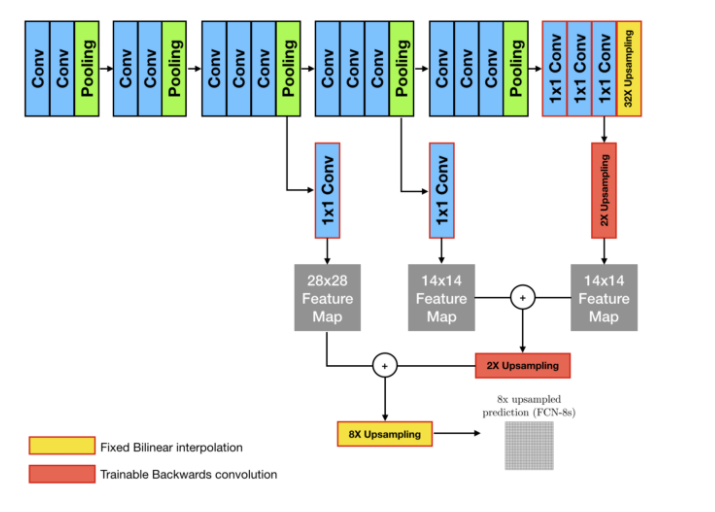
1x1 covolution layer를 통해 차원을 조정하고 Upsampling을 통해 activation map의 크기가 작은 마지막 layer 부터 크기를 맞춰가며 각 layer의 activation map 사이의 합이 이루어진다.
마지막엔 Upsampling을 통해 input image와 동일한 크기의 output을 얻는다.
마지막 Upsampling factor (8, 16, 32)에 따라 모델의 이름이 FCN-(N)s로 정해진다.
(크기 = width, height, 차원 = # of filter (channels))

가장 많은 skip connection이 이루어진 FCN-8s가 가장 G.T에 가까운 좋은 성능을 보였다.
Pretrained Model
Image Classification data로 pre-trained된 flatten layer가 아닌 채널에 대한 Avgpooling을 사용한 모델에서 마지막 layer의 weight를 그대로 1x1 convolution layer의 weight로 사용하여 sematic segmentation 모델을 구성하면 정확하게 segmentation이 이루어지지 않지만 어느 정도 의미 있는 결과를 낸다.
이는 Backbone model을 통과한 Feature map을 처리하는 Image Classification과 Sementic sementation task 모두 feature map의 채널의 정보를 class 정보로 변환한다는 공통점에서 기인한 결과다.
Reference
[3] Unpooling with Tensorflow: abenbihi.github.io/posts/2018-06-tf-unpooling/
[4] Deconvolutional and Checkboard Artifacts: distill.pub/2016/deconv-checkerboard/
[5] Naver Boostcamp AI-Tech "Sematic Segmentation" - 오태현 교수님
'AI > Deep Learning' 카테고리의 다른 글
| Multimodal Learning (0) | 2021.03.17 |
|---|---|
| R-CNN, Fast R-CNN, Faster R-CNN (0) | 2021.03.14 |
| Knowledge Distillation (0) | 2021.03.11 |
| Graph Neural Network (GNN) (0) | 2021.02.26 |
| GPT (0) | 2021.02.22 |



