
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 오블완
- 디퓨전모델
- ue5.4
- 폰트생성
- Font Generation
- Stat110
- Generative Model
- 딥러닝
- 언리얼엔진
- BERT
- WinAPI
- Unreal Engine
- ddpm
- GAN
- UE5
- dl
- multimodal
- CNN
- Diffusion
- deep learning
- cv
- 모션매칭
- userwidget
- motion matching
- Few-shot generation
- RNN
- WBP
- animation retargeting
- NLP
- 생성모델
- Today
- Total
목록AI/Deep Learning (99)
Deeper Learning
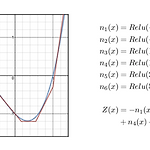 Universal Approximation Theorem
Universal Approximation Theorem
Universal Approximation Theroem one hidden layer로 모든 함수를 근사할 수 있다는 이론. 신경망은 함수를 근사하는데 매우 뛰어난 method로 여러 신경망 층을 쌓은 딥러닝이 비정형 데이터에서 최고의 성능을 보이고 있다. 하지만 one hidden layer만 사용하여도 존재하는 모든 연속함수를 근사할 수 있다. that a feed-forward network with a single hidden layer containing a finite number of neurons can approximate continuous functions on compact subsets of R 위 그림과 같이 연속함수들은 수많은 아래와 같은 함수들을 사용하면 근사가 가능하다. ..
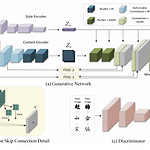 DG-Font: Deformable Generative Networks for Unsupervised Font Generation
DG-Font: Deformable Generative Networks for Unsupervised Font Generation
Abstract 현존 methods는 대부분 supervised learning, 매우 많은 paired data가 필요 image-to-image translation은 style을 텍스쳐와 색깔로 정의 냉림 Feature Deformation Skip Connection (FDSC)를 제시 predict pairs of displacement map employs the predicted maps to apply deformable convolution to the low-level feature maps from content encoder style-invariant feature 표현을 학습하기 위해 content encoder에 3개의 deformable convolutional layers를..
 Deformable Convolutional Networks
Deformable Convolutional Networks
(구조 이해를 위한 짧은 요약) Abstract CNN은 fixed geometric structure의 한계로 geometric transformation에 한계가 있다 CNN의 transformation capacity를 향상하기 위해 2개의 모듈을 제시 deformable convolution deformable RoI pooling spatial sampling location을 offset을 사용하여 변경, offset은 추가적인 supervised-learning 없이 target task를 수행하며 학습된다. 1. Introduction visual recognition task는 geometric variation, model geometric transformation을 핸들링할 수 있어..
 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Abstract CNN모델에서 depth, width, resolution 측면에서 세심한 밸런싱을 통해 더 좋은 성능을 이끌어낼 수 있다. 간단하며 효과적인 compound coefficient을 통해 depth, width, resolution의 dimension을 uniform 하게 scaling 하는 방법을 제시한다. EfficientNets은 기존 ConvNets의 성능을 뛰어넘었으며 EfficientNet-B7은 ImageNet에서 84.3% top-1 acc로 SOTA를 달성하였다. 기존 최고 성능 모델과 비교하였을 때 inference에서 8.4x smaller, 6.1x faster Transfer learning에도 좋은 성능을 보였다. (CIFAR-100, Flowers SOTA) 1..
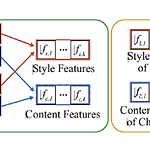 Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts
Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts
ABSTRACT few-shot generation(FFG)는 2가지 조건을 만족하여야 한다. target char의 global structure 보존 diverse local reference style의 표현 explicit 하게 component label을 주지 않고 MX-Font는 multiple style features를 추출한다. multiple expert들이 different local concepts을 표현한다. 각 expert들이 different local style에 특화될 수 있도록 weak supervision방식으로 component label을 이용한다. 각 expert들에게 component assign problem을 graph matching problem으로 정의..
 Few-shot Font Generation with Localized Style Representations and Factorization
Few-shot Font Generation with Localized Style Representations and Factorization
Abstract 기존 Few-shot font generation 모델은 style과 content의 disentanglement을 하고자 하였지만 이와 같은 접근법은 다양한 "local styles"을 표현하는데 한계가 있다 이는 복잡한 letter system(ex. Chinese)에 적합하지 않다 localized styles = component-wise style representations을 학습하는 방식으로 font generation하는 모델을 제안 reference glyph의 수를 줄이기위해 component-wise style을 component factor와 style factor의 product으로 정의한다. strong locality supervision (component의 ..
 CS231n - Lecture 8 ~ 13
CS231n - Lecture 8 ~ 13
복습이므로 전체적인 내용 리뷰가 아닌 그룹 스터디 중 토론 나눴던 주제 중심으로 정리. 이해하였던 내용을 떠올릴 수 있을 정도로만 정리 Lecture 8 Lecture 9 LeNet-5 conv - pool - conv - pool - fc -fc 형식의 모델 1998년 yann lecun AlexNet ILSVRC에서 작년에 비해 엄청난 성능 향상으로 winner CNN을 활용하는 method가 이후 활발하게 연구 ZFNet AlexNet과 매우 유사한 구조, kernel, filter, stride 등 hyperparameter를 조정 VGGNet 11x11 kernel을 사용하지 않고 3x3 kernel로만 깊게 layer를 구성 3x3 kernel을 깊게 쌓아 large receptive fiel..
 Few-shot Compositional Font Generation with Dual Memory
Few-shot Compositional Font Generation with Dual Memory
ABSTRACT 글자가 많은 언어에 대해 새 폰트를 만드는 것은 매우 노동집약적이고 시간이 많이 든다. 현존하는 폰트 생성 모델은 많은 reference image를 참고하지 못하면 디테일한 스타일을 살리지 못한다. 조합형 글자에 대해 적은 수의 샘플을 보고 하이퀄리티의 글자를 생성해내는 DM-Font를 제시하겠다 better quality, faithful stylization compared to SOTA font generation methods Introduction GAN base image-to-image translation 방식으로 폰트를 생성하는데 전의 method는 775개의 samples이 필요했다 기존 방식은 pre-trained된 모델에 새로운 reference image를 사용하..
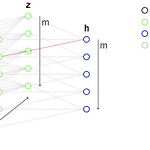 CS231n - Lecture 5 ~ 7
CS231n - Lecture 5 ~ 7
전체적인 내용 리뷰가 아닌 그룹 스터디 중 토론 나눴던 주제 중심으로 정리. Lecture 5 ~ 7 Sigmoid의 문제점 Saturated neuron kills gridients Not zero centered exp() is expensive 만약 input으로 모두 양수가 주어지면 w의 gradient는 모두 양수거나 모두 음수가 된다. w1, w2가 x, y축을 이루는 사분면을 생각해보면 만약 4사분면에 최적의 W가 존재할 경우 w1, w2의 grad는 각각 양수, 음수로 주어져야 빠른 수렴이 가능하다. 하지만 위 상황에서 이는 불가능하여 oscillation 형태로 수렴이 느려진다. Tanh zero centered saturated kill Relu no saturated kill comp..
 CS231n - Lecture 1 ~ 4
CS231n - Lecture 1 ~ 4
그룹 스터디로 복습 중, 간단하게 잊어버렸던 내용만 정리. Hinge loss 식은 위와 같다. true label에 대한 logits이 각 label에 대한 logits보다 1이상 클 경우 0의 loss를 가진다. +1은 arbitrary choice로 W의 scale에 따라 달라질 수 있는 값. 전체 모델에는 큰 영향이 없다. 크게 엇나가지 않은 값에 대해 loss를 주지 않아 기존에 잘 학습하고 있던 class의 예측값에 대한 변동에 robust하다. Q. W가 매우 작아 s값이 거의 0에 수렴하면 loss의 값은? -log(num of classes - 1) Q. true label을 굳이 빼고 식이 구성되는 이유? 자신 클래스가 포함되면 loss에 +1이 포함됨. zero로 minimun los..
 cGANs with Projection Discriminator
cGANs with Projection Discriminator
ABSTRACT conditional information을 projection을 기반으로 GAN의 discriminator에게 전달하는 이론을 제시한다. 기존 cGAN은 concat (embedding)형식으로 conditional information을 사용하고있다. Introduction 이안 굿펠로우의 GAN은 이미지 생성분야에서 SOTA 알고리즘이다. GAN의 Discriminator는 생성된 분포인 p_g(x)와 true target 분포인 q(x)의 divergence를 측정한다. 학습하면서 Discriminator (이하 D)가 Generator(이하 G)에게 더 정밀한 측정값을 보내주고 G는 이를 학습하여 target 분포에 가까운 이미지를 생성하는 방향으로 학습된다. cGAN은 clas..
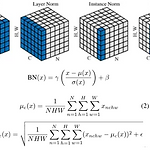 Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (AdaIN)
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (AdaIN)
Abstract 기존 neural style transfer의 경우 느린 iterative optimization process를 거친다. 리얼타임으로 동작하기에 너무 느린 속도 Adaptive instance normalization (AdaIN) layer는 content feature를 style feature의 분포와 맞춰준다. x는 content feature, y는 style feature를 의미한다. Introduction 주어진 이미지 x를 weight로 취급하여 gradient descent를 통해 반복적으로 업데이트하는 기존의 neural style transfer는 content, style 퀄리티가 뛰어나나 시간이 오래걸린다는 문제가 있으며 feed-forward method는 하나..
 XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet XLNet은 구글 연구팀이 발표한 모델로 당시 SOTA를 여러 자연어 처리 태스크에서 달성하였다. Transformer-XL을 개선한 모델로 eXtra Long Network로 트랜스포머 모델보다 더 긴 문맥을 볼 수 있다. AE방식의 언어모델인 BERT의 장점과 AR방식의 언어 모델인 GPT의 장점을 갖춘 Permutation language modeling을 사용함. BERT에는 몇가지 한계가 존재한다. MASK 토큰이 독립적으로 예측됨 Token 사이의 관계 학습이 불가능하다 ( 서로 독립적이라는 가정하에 있음 ) Embedding length의 제한으로 Segment 간 관계 학습 불가능 예를 들어 New York is the city 라는 시퀀스에서 New York 두 토큰이 [MAS..
 BERT (Bidirectional Encoder Representations from Transformers)
BERT (Bidirectional Encoder Representations from Transformers)
BERT BERT는 구글에서 개발한 언어 모델로 2018년 10월 논문 출시 후 다수의 NLP 태스크에서 SOTA를 기록하였다. BERT는 Transformer 기반 모델로 Encoder 부분만을 사용한다. Input은 두 개의 문장을 tokenizer를 사용하여 토큰화 시키고 문장의 시작에 special token인 [CLS]를 추가하고 두 문장 사이와 두 번째 문장의 끝에 [SEP] 토큰을 삽입한다. BERT의 input embedding은 input sentence의 tokenizing 형태인 token embedding, 앞 문장, 뒷 문장을 0 or 1로 나타내는 Segment Embedding, RNN과 달리 poistiion정보가 내포되어있지 않기 때문에 이를 위해 추가한 Position e..
 Multimodal Learning
Multimodal Learning
What is Multimodal Learning? Modality(a particular way of doing or experiencing something)가 다른 데이터를 사용하여 이루어지는 학습이다. 예를 들어, 이미지 데이터와 텍스트 데이터를 input으로 사용하는 image captioning task가 Multimodal Learning에 속한다. Challenge Multimodal Learning이 쉽지 않은 이유는 여러 가지가 있다. Different representations between modalities 이미지, 오디오, 텍스트, 3D 데이터는 그 표현 형식이 서로 달라 단순한 연산이 불가능하다. Unbalance between heterogeneous feature spac..
 R-CNN, Fast R-CNN, Faster R-CNN
R-CNN, Fast R-CNN, Faster R-CNN
2-stage detectors 2-stage detector는 객체가 존재할 가능성이 높은 영역(ROI: Region of Interest)을 추출하고 CNN을 통해 class와 boundig box의 위치를 찾는다. R-CNN, Fast R-CNN, Faster R-CNN 등이 2-stage detector에 속하며, YOLO, SSD 등이 1-stage detector에 속한다. 2-stage detectors인 R-CNN, Fast R-CNN, Faster R-CNN에 대해 매우 간략하게 차이점과 발전과정을 중심으로 작성하고자 한다. (자세한 각 알고리즘에 대한 설명은 후에 따로 작성할 예정) R-CNN Region Proposals with CNN(R-CNN)은 object detection을 ..
 Semantic Segmentation
Semantic Segmentation
Semantic segmentation Semantic segmentation은 이미지의 픽셀 별로 label을 부여하는 task로 각 instance 별로 구분은 하지 않는다. Fully Convolutional Network (FCN) FCN은 Semantic Segmentation을 수행 가능한 네트워크 구조 중 하나로 Image Classification을 위한 네트워크의 아키텍처에서 Fully Connected Layer를 Fully Connected Layer로 대체한 형태의 아키텍처를 가지는 모델이다. 1x1 convolution layer를 사용하여 activation map의 차원을 조절하며 마지막에는 class 갯수와 동일한 차원의 activation map이 나오게 된다. width와..
 Knowledge Distillation
Knowledge Distillation
Knowledge Distillation Knowledge distillation은 2014 NIPS 2014 workshop에서 Geoffrey Hinton, Oriol Vinyals, Jeff Dean이 발표한 논문 "Distilling the Knowledge in a Neural Network"에서 소개된 개념이다. Knowledge distillation은 Pre-trained 된 대용량의 Teacher Network의 정보를 비교적 작은 크기의 Student Network로 전이시키는 것이다. Teacher-Student Network Student 모델은 Teacher Model을 더 적은 parameter를 가지고 모방하도록 학습된다. unlabeled data만을 사용하여 student ..
 Graph Neural Network (GNN)
Graph Neural Network (GNN)
Node Embedding 정점 임베딩(Node Embedding)은 주어진 그래프에서 각 정점을 벡터 표현으로 변환하는 것이다. 그래프에서 정점간 유사도를 임베딩 된 벡터 공간에서 보존하는 것을 목표로 임베딩 한다. 인접성/거리/경로/중첩/랜덤워크 기반 접근법으로 similarity를 정의한다. 위의 정점 임베딩 방식은 학습의 결과로 임베딩된 정점의 벡터를 얻게 되는 Transductive(변환식) 방법이다. 변환식 정점 표현 방식은 학습이 진행된 후, 추가 정점에 대한 임베딩을 얻을 수 없으며 정점의 속성(Attribute) 정보를 활용할 수 없으며 모든 정점에 대한 임베딩을 저장할 공간이 필요하다는 문제점이 있다. 변환식 방법의 한계는 학습의 결과로 정점을 임베딩 시키는 인코더를 얻는 귀납식 임베딩..
 GPT
GPT
Self-Supervised Pre-Training Models 문서 분류, 감성 분석, 질의응답, 문장 유사성 파악, 원문함의 등 과제는 각각 주어진 과제에 알맞은 처리가 완료된 데이터가 필요하다. 미분류 corpus의 경우 매우 많으나 특정 목적을 위해 Labeling, 전처리가 완료된 데이터는 현저히 부족하다. 미분류 corpus를 사용하여 언어 모델을 학습시키고 특정 목적에 맞게 fine-tuning 하는 것으로 이를 어느 정도 해결할 수 있다. 비지도 학습인 미분류 corpus로 학습한 언어모델과 이를 supervised fine-tuning 하는 Self-supervised pre-training을 통해 언어이해(NLU)를 달성하는 것이 GPT의 목적이다. GPT-1 GPT-1은 OpenAI에..
 Adam Optimizer
Adam Optimizer
Momentum Momentum 방식은 Gradient Descent에 관성을 적용한 것으로 각 weight의 과거 시점의 정보를 저장하고 이를 활용하여 weight가 업데이트된다. γ는 momentum term으로 0.9를 기본값으로 대부분 사용한다. 위의 그림처럼 Oscillation이 발생할 경우 Momentum을 사용하면 이동방향이 계속해서 바뀔 경우 업데이트가 덜 되며, 같은 방향으로 업데이트가 계속될 경우 더 빠르게 업데이트되기 때문에 결과적으로 SGD보다 빠르게 global minima에 도달할 수 있다. Adagrad Adagrad(Adaptive Gradient)는 지금까지 각 변수의 누적 변화 정도를 기록하여, 변화가 많았던 변수는 step size를 작게 하고 변화가 없었..
 Autoencoder
Autoencoder
Autoencoder 오토 인코더는 위와 같이 input을 다시 재구성하는 구조로 hidden layer의 차원 수를 줄이거나, noise를 추가하는 등 제약을 통해 input이 그대로 output으로 복사되는 것을 막으며 데이터를 효율적으로 표현하는 방법을 학습한다. 차원 축소, feature extraction처럼 Autoencoder를 사용할 수 있는데 Encoder는 결국 input을 다시 재구성할 수 있는 가장 효율적인 feature를 추출해내는 과정과 유사하기 때문이다. Sparse Autoencoder hidden layer의 차원이 input의 차원보다 같거나 많으면 압축된 중요한 특성을 추출하지 못하고 원본을 그대로 복사하는 방향으로 학습이 이루어질 수 있다. 이를 방지하기 위해 Spar..
 Gradient Descent
Gradient Descent
Gradient Descent 경사하강법은 미분을 통해 얻은 Gradient Vector를 빼서 Weight를 업데이트하여 cost function을 줄이는 알고리즘이다. Loss fucntion의 기울기를 미분을 통해 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시킨다. Formula f(x): 최소값을 만드는 것이 목표인 Loss function xi: i번째 업데이트된 weights x0: x의 초기값 η: Learning Rate 위의 과정을 반복하여 f(x)의 값이 정해진 값 보다 작아질 때까지 이를 반복한다. #gradient: grad function #eps: epsilon var = init grad = gradient(var..
 Attention Mechanism
Attention Mechanism
Attention seq2seq 모델에서 RNN, LSTM, GRU 모두 초기시점의 정보가 희석되고 Decoder로 전달되는 Encoder의 마지막 hidden state (+ cell state) 하나에 모든 Encoder의 input의 정보를 담기가 어려워 정보 손실이 일어난다. 이를 해결하기 위해 seq2seq 모델에서 Decoder에서 output 각각의 계산이 모두 Encoder의 hidden state를 참고하여 이루어지는 Attention Mechanism이 제시되었다. 기계번역의 예시에서 Encoder가 특정 단어를 input으로 받아 도출한 output은 상응하는 단어를 번역하는 Decoder가 예측을 하는데 필요한 input과 유사할 것이라는 가정하에 만들어진 Attention Mech..
 Text similarity Model (CNN, MaLSTM)
Text similarity Model (CNN, MaLSTM)
텍스트 유사도 측정 자연어 처리에서 텍스트 유사도 문제는 Document의 유사도를 측정할 수 있는 모델을 만들어 해결이 가능하다. 두 질문이 유사한 질문일 경우 1, 아닐 경우 0으로 labeling 된 Quora Question Pairs 데이터셋을 CNN, MaLSTM 2가지 모델을 사용하여 텍스트 유사도를 측정해보겠다. Preprocessing 위와 같이 train 데이터는 2개의 질문인 question1, question2와 label인 is_duplicate로 이루어져 있다. Corpus의 특성상 ?와 : 같은 특수문자가 많아 정규표현식을 사용하여 영문을 제외한 특수문자나 숫자를 공백으로 대체한다. DataFrame에서 question1과 question2를 각각 list로 추출하여 할당하고 ..
 Deep Convolutional Generative Adversarial Networks (DCGAN)
Deep Convolutional Generative Adversarial Networks (DCGAN)
DCGAN GAN(Generative Adversarial Networks)은 Generator와 Discriminator 2개의 모델을 사용하여 실제 데이터와 비슷한 데이터를 생성하는 생성 모델이다. Random 한 Noise vector를 input으로 사용하는 Generator는 실제 데이터와 같은 shape의 데이터를 output으로 한다. Discriminator는 실제 데이터와, Generator가 생성한 데이터를 구별해내는 모델로 Binary Classification 모델이다. DCGAN은 Dense Net이 아닌 Convolutional NN를 사용하는 모델이다. DCGAN structure Generator는 위와 같은 구조로 위의 예시는 100d의 noise vector는 Transp..
 BLEU (Bilingual Evaluation Understudy Score)
BLEU (Bilingual Evaluation Understudy Score)
Why BLEU? 기계번역의 결과의 품질을 평가하기 위한 지표로 품질은 인간이 번역한 결과와 모델의 번역의 일치하는 정도와 같다. X: Le chat est sur le tapis Y1: The cat is on the mat Y2: There is a cat on the mat pred1: the the the the the the the pred2: Cat on the mat pred3: The cat the cat on the mat 위의 예시에서 보면 output의 길이가 다르고 pred1처럼 반복적인 단어의 sequence가 output일 경우 기존의 metrics의 사용이 힘들다. BLEU Bigrams BLEU를 먼저 예시로 들겠다. pred3: The cat the cat on the ma..
 Beam Search
Beam Search
Why Beam Search? 기계번역, 이미지 캡션 생성 등 ˆy가 둘 이상의 연속적인 Sequence가 되는 Decoder 형태의 모델에서 예측된 값은 다음 예측을 위한 input 값으로 피딩 된다. 위의 예시에서 Greedy Search를 사용하면 빠른 속도로 예측 과정이 완료되나 하나의 예측만을 고려하기 때문에 minor 한 변화에 영향을 받지 않아 최적의 예측을 하지 못활 확률이 Beam Seach보다 높다. 따라서 여러가지 예측을 하는 Beam Search를 사용한다. Beam Search vocab size가 10000인 예시에서 Encoder 부분을 지나고 처음으로 예측이 이루어지는 부분에서 구해야 하는 값은 argmaxyP(y|x)이다. ($y..
 Glove
Glove
Glove Glove(Global Vectors for Word Representation)은 워드 임베딩을 구현하는 방법론으로 count와 prediction 2가지 방법을 모두 사용하는 알고리즘이다. CBOW와 Skip-gram을 활용한 언어 모델에서는 Corpus 전체의 통계적 정보를 활용하지 않는다. Word2Vec 임베딩으로는 local context가 유일한 단어를 임베딩 하는데 필요한 정보가 되기 때문에 문법적 영향으로 주변 단어가 동일한 단어군은 비슷한 벡터 공간에 매핑된다. 뜻이 다르더라도 주변 단어가 비슷한 경우는 작은 단위의 Corpus에 자주 나타나며 이렇게 임베딩 된 단어 벡터는 특정 과제를 수행할 때 문제가 있을 수 있다. 이러한 문제점은 local window와 함께 전역적인 ..
 Word2Vec
Word2Vec
Word Embedding Vocabulary를 사용하여 One-hot encoding을 통해 비정형 텍스트 데이터를 수치형 데이터로 전환하여 input으로 사용이 가능하다. 하지만 오직 index하나로 단어의 정보를 표현하고 특정 단어의 index를 제외하고 모두 0으로 이루어진 one-hot vector를 사용하여 생기는 데이터의 Sparsity는 통계적 모델의 성공적인 학습을 방해한다. 특정 단어의 학습이 그 단어와 유사한 단어의 학습과 전혀 다른 과정이 되기 때문에 단어 간의 유사성의 학습이 쉽지 않다. 따라서 Word Embedding이 필요하다. Vocabulary의 size가 100,000 일 때 100,000 차원의 one-hot vector가 만들어진다. 하지만 Word Embedding..