
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Font Generation
- Unreal Engine
- NLP
- multimodal
- ue5.4
- GAN
- CNN
- 오블완
- Diffusion
- Stat110
- 생성모델
- dl
- 딥러닝
- animation retargeting
- BERT
- Few-shot generation
- 폰트생성
- WBP
- Generative Model
- 모션매칭
- 언리얼엔진
- ddpm
- WinAPI
- cv
- userwidget
- motion matching
- RNN
- 디퓨전모델
- deep learning
- UE5
- Today
- Total
목록딥러닝 (16)
Deeper Learning
 LDM: High-Resolution Image Synthesis with Latent Diffusion Models
LDM: High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer, (2021.12) [Ludwig Maximilian University of Munich & IWR, Heidelberg University, Runway ML] (이전 Diffusion Models paper review(DDPM, DDIM, Improved-DDPM 등)에서 다루었던 중복된 내용은 자세하게 적지 않았음) Abstract Diffusion model은 이미지 생성에서 좋은 성능을 보였고 재학습 없이 guidance를 주어 이미지 생성 프로세스를 조정할 수 있는 능력 또한 갖추고 있다 하지만 pixel level에서의 연산이 이루어지기 때문에 수백일의..
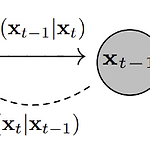 Diffusion Model 수식 정리
Diffusion Model 수식 정리
prerequisite: Diffusion Model에 대한 기초적인 이해 Diffusion Model $T$ = 전체 Timesteps 수 $x_T$ = forward process를 $T$ 번 적용한 마지막 Timestep $T$ 에서의 이미지 $x_0$ = 원본 이미지 Forward Process $$ q(x_t|x_{t-1}) = N(x_t, \sqrt{1-\beta_t}x_{t-1}, \beta_tI) $$ $\beta$ 는 noise(variance)의 강도를 조절하는 parameter로 DDPM 논문에서는 0.0001 ~ 0.02의 값을 사용 $\beta$ 가 선형적으로 timesteps에 따라(DDPM에서는 linear noise scheduler 사용) 0.0001에서 0.02까지 증가하..
 CLIP: Learning Transferable Visual Models From Natural Language Supervision
CLIP: Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim , Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever, (2021.02) Abstract SOTA 컴퓨터 비전 시스템은 정해진 object의 카테고리를 예측하도록 학습하는 것 지도학습 방식은 라벨링된 데이터를 요구하기 때문에 일반화, 활용성에 제약이 존재 raw text-image pair 데이터를 학습하면 지도학습에서 더 많은 소스를 활용할 수 있음 raw text-image pair 데이터로 이미지 representation 학습을 ..
 Few-Shot Unsupervised Image-to-Image Translation
Few-Shot Unsupervised Image-to-Image Translation
Ming-Yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen, Jan Kautz, [NVIDIA, Cornell University, Aalto University] (2019.05) Abstract Unsupervised image-to-image(i2i)는 여러 class 간 매핑을 학습하는 방법 최근 방법론들은 좋은 성과를 보였으나 학습과정에서 많은 수의 소스, 타깃 이미지를 필요로 하는 문제가 존재 인간은 매우 적은 수의 이미지로도 object를 잘 파악하는데에서 영감을 받아 few-shot 연구를 진행 저자는 새로운 모델 아키텍처, adversarial 학습 scheme을 함께 사용하여 few-shot generatio..
 FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer
FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer
Yitian Liu, Zhouhui Lian, [Wangxuan Institute of Computer Technology, Peking University, Beijing, China] (2022.10.13) Abstract 적은 데이터로 고품질의 중국어 폰트를 생성해내는 것은 어려운 일이며 현존하는 few-shot 폰트 생성 방식은 low-resolution의 획이 끊기는 폰트를 만드는데 그쳤다 이러한 문제를 해결하기 위해 본 논문은 고품질의 few-shot 생성이 가능한 FontTransformer를 제시 key idea는 prediction error가 쌓이는 것을 피하기 위한 parallel Transformer, 생성된 획의 퀄리티를 높이기 위한 serial Transformer의 사용 실제 ..
 GraphCodeBERT: Pre-training Code Representations with Data Flow
GraphCodeBERT: Pre-training Code Representations with Data Flow
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang and Ming Zhou [School of Computer Science and Engineering, Sun Yat-sen University, Beihang University, Peking University, Harbin Institute of Technology, Microsoft Research Asia, ..
 DeiT: Training data-efficient image transformers & distillation through attention
DeiT: Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Herve Jegou. Facebook AI. Sorbonne University. (2020.12) Abstract Image task에 pure attention 기반 모델이 활용되지만 large dataset에서 pre-training이 필수적이며 이는 활용에 한계를 가져옴 single computer에서 3일 동안 ImageNet dataset만 학습하여 top-1 acc 83.1%를 달성 attention을 통해 학습하는 distillation token을 도입한 transformer를 위한 teacher-student strategy를 제시 ..
 CoAtNet: Marrying Convolution and Attention for All Data Sizes
CoAtNet: Marrying Convolution and Attention for All Data Sizes
Zihang Dai, Hanxiao Liu, Quoc V. Le, Mingxing Tan Google Research, Brain Team (2021.06) Abstract Transformer 아직 vision task에서 SOTA convolutional network보다 성능이 떨어짐 Transformer는 더 큰 capacity를 가지지만 inductive bias의 부족으로 일반화 성능이 convolutional network에 비해 떨어짐 두 아키텍처의 장점을 결합하기 위해 hybrid model인 CoAtNets를 제시 CoAtNet의 key insights depthwise Convolution, Self-Attention은 간단한 relative attention을 통해 결합 가능 수직으..
 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo Microsoft Research Asia (2021.03) Abstract CV task를 위한 범용적인 Backbone 모델로 새로운 vision Transformer인 Swin Transformer를 제시 vision에 Transformer를 사용하기에는 visual entities의 scale 변동, high resolution pixels 등의 어려움이 있음 이를 해결하기 위해 Shifted windows를 사용하는 hierarchical Transformer를 제시 shifted windowing은 겹치지 않는 local window 한정으..
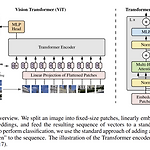 [Vision Transformer, ViT] An Image is Worth 16x16 Words: Transformers For Image Recognition At Scale
[Vision Transformer, ViT] An Image is Worth 16x16 Words: Transformers For Image Recognition At Scale
Alexey Dosovitskiy et al., (2020), Google Research, Brain Team Abstract 사실상 Transformer 구조가 NLP task에서 standard가 되었지만 vision task에서는 아직 적용에 한계가 있었음 Transformer는 CNN을 대체하지 못하고 CNN의 일부 컴포넌트를 대체하는 식으로 결합하여 사용되고 있었음 이미지 분류 태스크에서 pure transformer로 좋은 성능을 낼 수 있음 large datasets에서 pre-trained 한 ViT 모델은 mid-sized or small image recognition(ImageNet, CIFAR-100, VTAB, etc)에서 더 적은 computational cost를 필요로 하면..
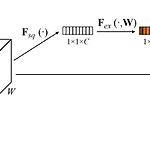 Squeeze-and-Excitation Networks (SE-Net)
Squeeze-and-Excitation Networks (SE-Net)
Abstract CNN의 메인 블록은 spatial, channel-wise information를 각 layer의 local receptive fields에서 결합하여 정보를 가지고 있는 feature를 만든다. 이전 연구들은 spatial encoding을 강화하는데 집중하였지만 저자는 channel relationship에 집중하여 "Squeeze-and-Excitation"(SE) block을 제시 SE block은 adaptive 하게 channel-wise feature를 recalibrate(재교정, 재보정)한다. computational cost가 크지 않으며 ILSVRC에서 1등을 차지 1. Introduction CNN은 필터들은 spatial, channel-wise 정보를 함께 사용..
 XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet XLNet은 구글 연구팀이 발표한 모델로 당시 SOTA를 여러 자연어 처리 태스크에서 달성하였다. Transformer-XL을 개선한 모델로 eXtra Long Network로 트랜스포머 모델보다 더 긴 문맥을 볼 수 있다. AE방식의 언어모델인 BERT의 장점과 AR방식의 언어 모델인 GPT의 장점을 갖춘 Permutation language modeling을 사용함. BERT에는 몇가지 한계가 존재한다. MASK 토큰이 독립적으로 예측됨 Token 사이의 관계 학습이 불가능하다 ( 서로 독립적이라는 가정하에 있음 ) Embedding length의 제한으로 Segment 간 관계 학습 불가능 예를 들어 New York is the city 라는 시퀀스에서 New York 두 토큰이 [MAS..
 BERT (Bidirectional Encoder Representations from Transformers)
BERT (Bidirectional Encoder Representations from Transformers)
BERT BERT는 구글에서 개발한 언어 모델로 2018년 10월 논문 출시 후 다수의 NLP 태스크에서 SOTA를 기록하였다. BERT는 Transformer 기반 모델로 Encoder 부분만을 사용한다. Input은 두 개의 문장을 tokenizer를 사용하여 토큰화 시키고 문장의 시작에 special token인 [CLS]를 추가하고 두 문장 사이와 두 번째 문장의 끝에 [SEP] 토큰을 삽입한다. BERT의 input embedding은 input sentence의 tokenizing 형태인 token embedding, 앞 문장, 뒷 문장을 0 or 1로 나타내는 Segment Embedding, RNN과 달리 poistiion정보가 내포되어있지 않기 때문에 이를 위해 추가한 Position e..
 Multimodal Learning
Multimodal Learning
What is Multimodal Learning? Modality(a particular way of doing or experiencing something)가 다른 데이터를 사용하여 이루어지는 학습이다. 예를 들어, 이미지 데이터와 텍스트 데이터를 input으로 사용하는 image captioning task가 Multimodal Learning에 속한다. Challenge Multimodal Learning이 쉽지 않은 이유는 여러 가지가 있다. Different representations between modalities 이미지, 오디오, 텍스트, 3D 데이터는 그 표현 형식이 서로 달라 단순한 연산이 불가능하다. Unbalance between heterogeneous feature spac..
 R-CNN, Fast R-CNN, Faster R-CNN
R-CNN, Fast R-CNN, Faster R-CNN
2-stage detectors 2-stage detector는 객체가 존재할 가능성이 높은 영역(ROI: Region of Interest)을 추출하고 CNN을 통해 class와 boundig box의 위치를 찾는다. R-CNN, Fast R-CNN, Faster R-CNN 등이 2-stage detector에 속하며, YOLO, SSD 등이 1-stage detector에 속한다. 2-stage detectors인 R-CNN, Fast R-CNN, Faster R-CNN에 대해 매우 간략하게 차이점과 발전과정을 중심으로 작성하고자 한다. (자세한 각 알고리즘에 대한 설명은 후에 따로 작성할 예정) R-CNN Region Proposals with CNN(R-CNN)은 object detection을 ..
 Semantic Segmentation
Semantic Segmentation
Semantic segmentation Semantic segmentation은 이미지의 픽셀 별로 label을 부여하는 task로 각 instance 별로 구분은 하지 않는다. Fully Convolutional Network (FCN) FCN은 Semantic Segmentation을 수행 가능한 네트워크 구조 중 하나로 Image Classification을 위한 네트워크의 아키텍처에서 Fully Connected Layer를 Fully Connected Layer로 대체한 형태의 아키텍처를 가지는 모델이다. 1x1 convolution layer를 사용하여 activation map의 차원을 조절하며 마지막에는 class 갯수와 동일한 차원의 activation map이 나오게 된다. width와..