
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 폰트생성
- Stat110
- 모션매칭
- Generative Model
- NLP
- deep learning
- WBP
- WinAPI
- UE5
- userwidget
- RNN
- dl
- 언리얼엔진
- multimodal
- ddpm
- Unreal Engine
- ue5.4
- BERT
- Diffusion
- motion matching
- 딥러닝
- Few-shot generation
- inductive bias
- Font Generation
- GAN
- cv
- 생성모델
- 디퓨전모델
- CNN
- animation retargeting
- Today
- Total
목록AI (107)
Deeper Learning
 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, Denny Zhou (2022.01) [Google Research, Brain Team] Abstract일련의 중간 추론 과정을 뜻하는 사고의 흐름, Chain-of-Thought(이하 COT)를 사용하여 Large Language Model(이하 LLM)의 복잡한 추론성능을 향상시키는 방법을 소개한다. 간단하게 몇 가지 예시를 주는 방식으로 만든 COT 프롬프팅으로도 LLM의 추론 능력이 향상되었다.Arithmetic, Commonsence, Symbolic Reasoning 에서 더 좋은 퍼포먼스를 보였으며 PaLM 5..
 SVM: Support Vector Machine (1)
SVM: Support Vector Machine (1)
Support Vector Machine 빨간점, 녹색점이 각각 negative, positive class이며 feature의 dimension이 2인 데이터를 나타낸 그림이 있다. 성능이 좋은 분류모델의 Decision boundary를 그린다고 하면 보통 위의 실선을 그리게 될 것인데 이 때, 경계 주변의 점들이 주로 decision boundary의 개형을 결정하게 된다. 이를 모델링 한것이 Support vector machine이다 (이하 SVM) Separate Hyperplane Constraints 위의 예시는 2차원으로 class를 나누는 경계인 hyperplane이 line으로 표현되며, 3차원에서는 plane이 hyperplane이 될 것이다. SVM의 목표는 데이터를 잘 분류할 수..
 직관과 MLE, MAP(2)
직관과 MLE, MAP(2)
(이전글에 이어서 작성) 여기에서 의문이 생기는데 동전을 5번 던져서 모두 앞면이 3번 나오면 MLE 관점으로는 60% 확률로 앞면이 나온다고 추정하고 동전을 100번 던져서 앞면이 60번 나올 때도 마찬가지로 60% 확률로 앞면이 나온다고 추정하는데 괜찮은가 동전은 보통 50% 확률로 앞면이 나온다는 사전지식이 있는데 $n$ 이 작을 때 이 결과를 신뢰해도 괜찮은가 위 의문은 모두 사전지식(prior knowledge)을 반영하지 않기 때문에 생기는 의문으로 사전지식을 반영하여 최적의 추정값을 고르는 다음 글에서는 이어서 MAP 관점으로 다시 문제를 해결해 보겠다. 사전지식을 포함하여 모델링할 때는 Bayes Rule을 사용한다 $$ P(\theta|D) = \frac{P(D|\theta)P(\thet..
동전을 5번 던져서 앞면, 앞면, 뒷면, 앞면, 뒷면이 나왔을 때, 동전을 한 번 던져서 앞면이 나올 확률을 추정하면 직관적으로 3/5라고 생각하는데 정말 그럴까? 위 질문에 대한 답을 MLE 관점으로 찾아보자. Binomal Distribution, Bernoulli experiment 한 번 동전을 던지면 앞면(H) 또는 뒷면(T)가 나오게 되는데, 이는 discrete하고 가능한 값이 2개(H,T)가 전부인 베르누이 분포를 따른다. 매 시행이 동일한 베르누이 분포를 따르며 독립적이기 때문에 동전을 5번 던질 때 1,2,3,4,5 번째 시행에서 동전이 앞면이 나오는 횟수를 나타내는 확률변수 $X_1,X_2,X_3,X_4,X_5$ 는 i.i.d이기 때문에 동전을 5번 던질 때 앞면이 나오는 횟수를 나타..
 LDM: High-Resolution Image Synthesis with Latent Diffusion Models
LDM: High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer, (2021.12) [Ludwig Maximilian University of Munich & IWR, Heidelberg University, Runway ML] (이전 Diffusion Models paper review(DDPM, DDIM, Improved-DDPM 등)에서 다루었던 중복된 내용은 자세하게 적지 않았음) Abstract Diffusion model은 이미지 생성에서 좋은 성능을 보였고 재학습 없이 guidance를 주어 이미지 생성 프로세스를 조정할 수 있는 능력 또한 갖추고 있다 하지만 pixel level에서의 연산이 이루어지기 때문에 수백일의..
 Score-Based Generative Modeling through Stochastic Differential Equations
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, Ben Poole, (2020.11) [Stanford, Google] Why score function? 생성모델을 학습한다는 것은 데이터 분포 $p_\theta(x)$ 를 근사하는 것과 같다. likelihood based 모델에서는 직접적으로 pmf 또는 pdf를 모델링하는데 아래 식처럼 학습가능한 parameter set $\theta$ 로 parameterize된 Real-valued function $f_\theta(x)$ 를 사용하여 pdf를 정의할 수 있다. $$ p_\theta(x) = \frac{e^{-f_\theta}(x)}{Z_\th..
 Score-based Generative Models과 Diffusion Probabilistic Models과의 관계
Score-based Generative Models과 Diffusion Probabilistic Models과의 관계
Generative Modeling by Estimating Gradients of the Data Distribution https://arxiv.org/abs/1907.05600 Score-based Generative Model의 개념을 소개한 논문 Given this dataset, the goal of generative modeling is to fit a model to the data distribution such that we can synthesize new data points at will by sampling from the distribution. 생성모델에서 목표는 주어진 데이터셋을 활용하여 모델이 데이터 분포를 실제 데이터 분포와 가깝게 근사하고 구한 데이터 분포를 활용하여..
 Diffusion Models Beat GANs on Image Synthesis
Diffusion Models Beat GANs on Image Synthesis
Prafulla Dhariwal, Alex Nichol, (2021.05) [OpenAI] Abstract Diffusion 모델이 현재 SOTA 생성 모델을 뛰어넘는 샘플 이미지 퀄리티를 달성할 수 있음을 본 논문에서 소개 unconditional image 생성에서는 Ablation study를 통해 찾은 더 나은 아키텍처를 적용하였고 conditional image 생성에서 classifier의 gradient를 활용하여 더 좋은 샘플 퀄리티와, fidelity & diversity trade-off를 조정할 수 있는 classifier-guidance를 제시 Diffusion 모델의 장점은 distribution coverage를 유지한 채 25 forward step만으로도 BigGAN-deep..
 Improved-DDPM: Improved Denoising Diffusion Probabilistic Models
Improved-DDPM: Improved Denoising Diffusion Probabilistic Models
Alex Nichol, Prafulla Dhariwal (2021.02) [openAI] Abstract DDPM이 간단한 변경으로 높은 log-likelihoods 달성할 수 있다는 것을 보임 reverse diffusion 과정의 분산을 학습하면 더 적은 forward process로 큰 퀄리티 차이 없이 sampling이 가능하다는 것을 발견 GAN과 DDPM이 얼마나 타겟 분포를 커버하는지 비교하기 위해 precision, recall 사용 연산량, model capacity에 따라 샘플 퀄리티와 likelihood가 부드럽게 scaling 되는 것을 확인 https://github.com/openai/improved-diffusion GitHub - openai/improved-diffusion..
 DDIM: Denoising Diffusion Implicit Models
DDIM: Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng & Stefano Ermon, (2020.10) [Stanford University] Abstract DDPM(Denoising diffusion probabilistic models)은 adversarial 학습 없이 고품질의 이미지 생성에 성공하였으나 sample을 만들기 위해 많은 스텝의 Markov chain을 거쳐야 하는 문제가 존재 sampling을 빠르게 하기 위해 저자는 DDIM(denoising diffusion implicit models)을 제시 DDPM에서 생성 과정은 Markovian diffusion process의 역으로 정의되어있음 DDIM은 DDPM을 non-Markovian diffusion process의 class로 일..
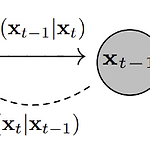 Diffusion Model 수식 정리
Diffusion Model 수식 정리
prerequisite: Diffusion Model에 대한 기초적인 이해 Diffusion Model $T$ = 전체 Timesteps 수 $x_T$ = forward process를 $T$ 번 적용한 마지막 Timestep $T$ 에서의 이미지 $x_0$ = 원본 이미지 Forward Process $$ q(x_t|x_{t-1}) = N(x_t, \sqrt{1-\beta_t}x_{t-1}, \beta_tI) $$ $\beta$ 는 noise(variance)의 강도를 조절하는 parameter로 DDPM 논문에서는 0.0001 ~ 0.02의 값을 사용 $\beta$ 가 선형적으로 timesteps에 따라(DDPM에서는 linear noise scheduler 사용) 0.0001에서 0.02까지 증가하..
 DDPM: Denoising Diffusion Probabilistic Models
DDPM: Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, Pieter Abbeel, (2020.06) [UC Berkeley] [이후 Cold Diffusion 논문에서 Gaussian Noise가 아닌 다른 Noise를 사용하여 학습이 가능함을 보였기 때문에, 해당 파트에 대한 수식은 간단하게 다룸, Langevin dynamics 또한 다루지 않음] Abstract 비평형 열역학에서 영감을 받은 latent variable model인 diffusion 확률 모델을 사용한 고품질의 이미지 생성 방법론을 제시 diffusion 확률 모델, denoising score matching, Langevin dynamics의 관계를 활용하여 디자인한 weighted variational bound로 학습 CIFAR-10 u..
 SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation
SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation
Jie Zhou, Yefei Wang, Yiyang Yuan, Qing Huang, Jinshan Zeng (2022.11) Abstract 효과적인 가이드 정보가 없어 GAN-based 모델이 mode collapse 문제를 겪고 있음 본 연구는 skeleton guided channel expansion(이하 SGCE) 모듈로 skeleton 정보를 generator에게 channel expansion 방식으로 주어 local, global structure를 파악하게 하는 새로운 guidance 방식을 제시 SGCE 모듈을 통해 mode collapse 문제가 완화되었으며 실험을 통해 이를 보임 4개의 metrics에서 SOTA를 달성 다른 중국어 폰트 생성 모델에도 plug-and-play 모듈로..
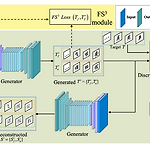 StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
Jinshan Zeng, Yefei Wang, Qi Chen, Yunxin Liu, Mingwen Wang, and Yuan Yao, (2022.11) Abstract 현재 중국어 폰트 생성의 주류 방식은 GAN 기반 모델, 하지만 GAN 기반 모델은 mode collapse 문제를 겪고 있음 이 문제를 해결하기 위해 one-bit stroke encoding과 few-shot semi-supervised scheme으로 local, global structure 정보를 찾아내는 방식을 제시 해당 아이디어를 기반으로 본 논문은 stroke encoding과 few-shot semi-supervised scheme을 CycleGAN과 결합하여 mode collapse 문제를 완화한 StrokeGAN+를 제..
 Zero-Shot Text-to-Image Generation
Zero-Shot Text-to-Image Generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever (2021.02) Abstract Text-to-Image(이하 TTI) generation은 고정된 데이터셋을 학습하기 위한 더 좋은 모델링 가정을 찾는 방향으로 연구가 집중되었음 이러한 가정은 복잡한 아키텍처, auxiliary loss 그리고 object part labels, segmentation mask와 같은 side information을 수반 하지만 저자는 text와 image token을 하나의 stream으로 처리하여 transformer-based 아키텍처로 autoregressive하게 ..
 MLE(Maximum Likelihood Estimation), MAP(Maximum A Posterior)
MLE(Maximum Likelihood Estimation), MAP(Maximum A Posterior)
https://dlaiml.tistory.com/entry/Bayes-theorem Bayes' theorem 농어와 연어를 분류하는 문제 생선의 길이를 기준으로 농어, 연어를 분류 길이를 $x$, 물고기의 종류를 $w$ 라고 하자 물고기가 농어면 $w = w_1$, 연어면 $w = w_2$로 정의 Prior 사전확률인 Prior는 사전 dlaiml.tistory.com (Bayes theroem 포스팅에 이어서) Introduction 물고기의 길이 $x$, 물고기의 무게 $k$, 물고기의 길이로 물고기의 무게를 예측하는 회귀 문제를 예시로 들겠다. 필요로 하는것은 모든 $x$에 대해서 모든 $k$를 아는 함수 $k=g(x)$ (물고기의 길이에 따른 무게의 확률 밀도 함수) 이 함수를 parameter..
 CLIP: Learning Transferable Visual Models From Natural Language Supervision
CLIP: Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim , Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever, (2021.02) Abstract SOTA 컴퓨터 비전 시스템은 정해진 object의 카테고리를 예측하도록 학습하는 것 지도학습 방식은 라벨링된 데이터를 요구하기 때문에 일반화, 활용성에 제약이 존재 raw text-image pair 데이터를 학습하면 지도학습에서 더 많은 소스를 활용할 수 있음 raw text-image pair 데이터로 이미지 representation 학습을 ..
 Few-Shot Unsupervised Image-to-Image Translation
Few-Shot Unsupervised Image-to-Image Translation
Ming-Yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen, Jan Kautz, [NVIDIA, Cornell University, Aalto University] (2019.05) Abstract Unsupervised image-to-image(i2i)는 여러 class 간 매핑을 학습하는 방법 최근 방법론들은 좋은 성과를 보였으나 학습과정에서 많은 수의 소스, 타깃 이미지를 필요로 하는 문제가 존재 인간은 매우 적은 수의 이미지로도 object를 잘 파악하는데에서 영감을 받아 few-shot 연구를 진행 저자는 새로운 모델 아키텍처, adversarial 학습 scheme을 함께 사용하여 few-shot generatio..
 FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer
FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer
Yitian Liu, Zhouhui Lian, [Wangxuan Institute of Computer Technology, Peking University, Beijing, China] (2022.10.13) Abstract 적은 데이터로 고품질의 중국어 폰트를 생성해내는 것은 어려운 일이며 현존하는 few-shot 폰트 생성 방식은 low-resolution의 획이 끊기는 폰트를 만드는데 그쳤다 이러한 문제를 해결하기 위해 본 논문은 고품질의 few-shot 생성이 가능한 FontTransformer를 제시 key idea는 prediction error가 쌓이는 것을 피하기 위한 parallel Transformer, 생성된 획의 퀄리티를 높이기 위한 serial Transformer의 사용 실제 ..
 GraphCodeBERT: Pre-training Code Representations with Data Flow
GraphCodeBERT: Pre-training Code Representations with Data Flow
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang and Ming Zhou [School of Computer Science and Engineering, Sun Yat-sen University, Beihang University, Peking University, Harbin Institute of Technology, Microsoft Research Asia, ..
 CodeBERT:A Pre-Trained Model for Programming and Natural Languages
CodeBERT:A Pre-Trained Model for Programming and Natural Languages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, Ming Zhou, [Research Center for Social Computing and Information Retrieval, Harbin Institute of Technology, China, The School of Data and Computer Science, Sun Yat-sen University, China, Microsoft Research Asia, Beijing, China, Microsoft Search Technology Center Asia, Beijing, C..
 Longformer: The Long-Document Transformer
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, Arman Cohan [Allen Institute for Artificial Intelligence, Seattle, WA, USA] (2020.04) Abstract Transformer 기반 모델은 sequence 길이에 따라 quadratic 하게 증가하는 계산 복잡도를 가지는 self-attention 연산으로 인해 긴 sequence를 처리하지 못하였다 sequence length에 따라 선형적으로 계산량이 증가하여 수천 개 이상의 토큰을 처리할 수 있는 Longformer를 제시 Longformer의 attention 메커니즘은 drop-in replacement, local windowed attention text8, enwik8에서..
 Few-Shot Font Generation by Learning Fine-Grained Local Styles
Few-Shot Font Generation by Learning Fine-Grained Local Styles
Licheng Tang, Yiyang Cai, Jiaming Liu, Zhibin Hong, Mingming Gong, Minhu Fan, Junyu Han, Jingtuo Liu, Errui Ding, Jingdong Wang [Baidu Inc, University of California, Berkeley, University of Melbourne] (2022.05) Abstract **Few-shot font generation(FFG)**는 노동 cost를 크게 줄여주어 주목을 받고 있는 기술 이전의 연구들은 reference glyph의 content와 style을 global, component-wise하게 disentangle 하는 방식으로 FFG에 접근 하지만 glyph의 style은 ..
 DeBERTa: Decoding-enhanced BERT with Disentangled Attention
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen, [Microsoft Research, Microsoft Dynamics 365 AI] (2020.06) Abstract 두 새로운 테크닉으로 BERT, RoBERTa를 향상한 새로운 모델 아키텍처 **DeBERTa(Decoding-enhanced BERT with disentangled attention)**을 제시 첫 번째 테크닉은 disentangled attention mechanism 각 단어는 content와 position을 각각 encode하는 2개의 벡터로 표현 단어끼리의 attention weight 또한 content, relative position 각각에 disentangled matr..
 T5: Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer
T5: Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu [Google] (2019.10) Abstract Transfer learning은 NLP에서 강력한 기술로 부상하였다 모든 text 기반 language 문제를 text-to-text 형식으로 바꾸는 unified framework을 제시하여 NLP에서의 transfer learning에 대해 탐구 논문의 체계적인 연구는 pre-training objectives, 아키텍처, unlabeled 데이터셋, transfer approach 등 요인들을 여러 language understandi..
 BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer [Facebook AI] (2019.10) Abstract sequence-to-sequence model을 사전학습시키기 위한 denoising autoencoder BART를 제시 BART는 text를 임의의 noise 함수로 corrupt시키고 모델은 corrupted text를 다시 original text로 재구성하는 방식으로 학습 기본 Transformer 기반 neural machine translation 아키텍처를 사용한 단순한 구조임에도 BERT, GPT 등 여러 최근 사..
 M3AE: Multimodal Masked Autoencoders Learn Transferable Representations
M3AE: Multimodal Masked Autoencoders Learn Transferable Representations
Xinyang Geng, Hao Liu, Lisa Lee, Dale Schuurmans, Sergey Levine, Pieter Abbeel, [UC Berkeley, Google Brain] (2022.05.31) Abstract 다양한 multimodal data를 학습하는 scalable 모델을 만드는 것은 아직까지 어려움이 많다 vision-language data에서 주된 접근법은 modality 마다 separate encoder를 학습하는 contrastive learning contrastive learning은 효율적이지만, 사용한 data augmentation에 따른 sampling bias로 downstream task에서 성능이 감소하는 문제가 존재 contrastive learn..
 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning, [Google Brain] [Stanford University] (2020.03) Abstract Masked language modeling (MLM)은 input의 몇몇 token을 [MASK] token으로 바꾸고 원래 token을 재구성하는 방식으로 학습 MLM으로 학습한 모델은 downstream NLP task에 전이학습 하였을 때 성능 향상이 있었으나 효과를 보기 위해서는 많은 계산량을 요구한다 (비효율적인 sampling) 대안으로 저자는 sample-efficient pre-training task인 replaced token detection을 제시한다 token을 ..
 ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut, [Google Research][Toyota Technological Institute at Chicago], (2019.09) Abstract 자연어 표현을 사전학습 시킬 때 model size를 키우면 대체로 downstream task의 성능이 향상된다 하지만 model이 커짐에 따라 training time과 GPU, TPU memory 한계의 문제를 겪게 됨 이러한 문제를 해결하기 위해 BERT보다 더 적은 memory를 소모하고 학습 속도가 빠른 ALBERT를 제시 inter-sentence coherence를 모델링하기 위해 self..
 RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, Facebook AI, (2019.07) Abstract 언어모델 사전학습은 큰 성능향상을 가져오지만 여러 접근법에 대한 비교가 어려움 BERT의 여러 주요 hyperparameters, training data size의 효과를 정밀하게 측정한 replication study를 제시 BERT가 undertrained 되었고 성능향상의 여지가 있음을 확인 저자가 제시한 모델은 GLUE, RACE, SQuAD에서 SOTA를 달성 1. Introduction ELMo, GPT..