
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- motion matching
- animation retargeting
- RNN
- Diffusion
- ddpm
- CNN
- dl
- NLP
- Few-shot generation
- 언리얼엔진
- UE5
- ue5.4
- 디퓨전모델
- GAN
- cv
- 폰트생성
- Stat110
- 모션매칭
- BERT
- userwidget
- WinAPI
- 오블완
- Unreal Engine
- Generative Model
- WBP
- multimodal
- Font Generation
- 딥러닝
- deep learning
- 생성모델
- Today
- Total
목록전체 글 (220)
Deeper Learning
 DeBERTa: Decoding-enhanced BERT with Disentangled Attention
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen, [Microsoft Research, Microsoft Dynamics 365 AI] (2020.06) Abstract 두 새로운 테크닉으로 BERT, RoBERTa를 향상한 새로운 모델 아키텍처 **DeBERTa(Decoding-enhanced BERT with disentangled attention)**을 제시 첫 번째 테크닉은 disentangled attention mechanism 각 단어는 content와 position을 각각 encode하는 2개의 벡터로 표현 단어끼리의 attention weight 또한 content, relative position 각각에 disentangled matr..
 T5: Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer
T5: Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu [Google] (2019.10) Abstract Transfer learning은 NLP에서 강력한 기술로 부상하였다 모든 text 기반 language 문제를 text-to-text 형식으로 바꾸는 unified framework을 제시하여 NLP에서의 transfer learning에 대해 탐구 논문의 체계적인 연구는 pre-training objectives, 아키텍처, unlabeled 데이터셋, transfer approach 등 요인들을 여러 language understandi..
 BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer [Facebook AI] (2019.10) Abstract sequence-to-sequence model을 사전학습시키기 위한 denoising autoencoder BART를 제시 BART는 text를 임의의 noise 함수로 corrupt시키고 모델은 corrupted text를 다시 original text로 재구성하는 방식으로 학습 기본 Transformer 기반 neural machine translation 아키텍처를 사용한 단순한 구조임에도 BERT, GPT 등 여러 최근 사..
 M3AE: Multimodal Masked Autoencoders Learn Transferable Representations
M3AE: Multimodal Masked Autoencoders Learn Transferable Representations
Xinyang Geng, Hao Liu, Lisa Lee, Dale Schuurmans, Sergey Levine, Pieter Abbeel, [UC Berkeley, Google Brain] (2022.05.31) Abstract 다양한 multimodal data를 학습하는 scalable 모델을 만드는 것은 아직까지 어려움이 많다 vision-language data에서 주된 접근법은 modality 마다 separate encoder를 학습하는 contrastive learning contrastive learning은 효율적이지만, 사용한 data augmentation에 따른 sampling bias로 downstream task에서 성능이 감소하는 문제가 존재 contrastive learn..
 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning, [Google Brain] [Stanford University] (2020.03) Abstract Masked language modeling (MLM)은 input의 몇몇 token을 [MASK] token으로 바꾸고 원래 token을 재구성하는 방식으로 학습 MLM으로 학습한 모델은 downstream NLP task에 전이학습 하였을 때 성능 향상이 있었으나 효과를 보기 위해서는 많은 계산량을 요구한다 (비효율적인 sampling) 대안으로 저자는 sample-efficient pre-training task인 replaced token detection을 제시한다 token을 ..
 ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut, [Google Research][Toyota Technological Institute at Chicago], (2019.09) Abstract 자연어 표현을 사전학습 시킬 때 model size를 키우면 대체로 downstream task의 성능이 향상된다 하지만 model이 커짐에 따라 training time과 GPU, TPU memory 한계의 문제를 겪게 됨 이러한 문제를 해결하기 위해 BERT보다 더 적은 memory를 소모하고 학습 속도가 빠른 ALBERT를 제시 inter-sentence coherence를 모델링하기 위해 self..
 RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, Facebook AI, (2019.07) Abstract 언어모델 사전학습은 큰 성능향상을 가져오지만 여러 접근법에 대한 비교가 어려움 BERT의 여러 주요 hyperparameters, training data size의 효과를 정밀하게 측정한 replication study를 제시 BERT가 undertrained 되었고 성능향상의 여지가 있음을 확인 저자가 제시한 모델은 GLUE, RACE, SQuAD에서 SOTA를 달성 1. Introduction ELMo, GPT..
 [Statistics 110] Law of the unconscious statistician (LOTUS)
[Statistics 110] Law of the unconscious statistician (LOTUS)
LOTUS law of the unconscious statistician (무의식적인 통계학자의 법칙, 이하 LOTUS) 통계학에서 확률변수 X의 함수 g(X) 의 분포를 모르는 상황에서도 g(X)의 기댓값 E(g(X))를 계산할 수 있도록 해주는 theorem Formula 1. discrete random variable X, f_X는 Probability mass function(pmf) 2. continuous random variable X, fX는 probability density function(pdf) Example 포아송 확률변수 X의 확률 분포의 기댓값, 분산을 구하는 문제, 우선 기댓값을 구해보면 매클로린 급수를 이용할 수 있도록 식을 유도 분산을 구하기..
 [Statistics 110] Universality of Uniform distribution
[Statistics 110] Universality of Uniform distribution
Universality of Uniform distribution(균등분포의 보편성) Uniform distribution을 사용하여 임의의 확률분포를 만들어낼 수 있는 성질 condition u∼Unif[0,1], F는 원하는 분포의 cdf (단 F는 증가함수, 연속함수) F는 cdf이므로 0이상 1이하의 값을 가진다. F를 cdf로 가지는 확률변수 X를 구하는 방법 X=F−1(u) 이면 X의 cdf는 F를 따름 proof P(X≤x)=P(F−1(u)≤x) (가정에 의해) 양변에 역함수를 적용하면 (앞서 언급한 F에 대한 제약에 의해 부등호의 방향은 동일) P(F−1(u)≤x)=P(u≤F(x))..
 VQ-VAE: Neural Discrete Representation Learning
VQ-VAE: Neural Discrete Representation Learning
Aaron van den Oord, Oriol Vinyals, Koray Kavukcuoglu, Deepmind. (2017.11) Abstract unsupervised로 유용한 representation을 학습하는 것은 머신러닝에서 쉽지 않다 discrete representation을 학습하는 간단하고 강력한 generative model: Vector Quantised Variational Autoencoder(VQ-VAE)를 제시 encoder의 output이 discrete, prior가 static이 아닌 학습된다는 점이 VAE와의 차이점 discrete representation 학습을 위해 vector quantisation(이하 VQ)을 활용 VQ는 posterior collapse를 ..
 f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization
f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization
Sebastian Nowozin, Botond Cseke, Ryota Tomioka. (2016) Abstract Generative neural sampler는 feedforward NN을 통해 샘플링하는 probabilistic model sampling과 도함수를 쉽게 계산할 수 있지만 likelihood, marginalization을 계산할 수 없음 generative-adversarial approach가 더 일반적인 variational divergence estimation approach의 special case임을 논문에서 제시 모든 f-divergence를 generative neural sampler를 학습시킬 때 사용할 수 있음 다양한 divergence function을 사용하는..
 GAN: Generative Adversarial Nets
GAN: Generative Adversarial Nets
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Universite de Montreal (2014.06) Abstract 데이터 분포를 파악하는 generative model G와 sample이 training data에서 온 것인지 생성된 것인지 판별하는 discriminator D를 적대적인 프로세스로 동시에 학습하는 생성모델 프레임워크를 제시 G는 D가 제대로 판별하지 못하도록 학습되는 minimax two-player game G와 D는 MLP로 구성하였으며 역전파를 통해 학습이 가능한 모델 Ma..
 [Statistics 110] 확률변수와 확률분포
[Statistics 110] 확률변수와 확률분포
확률변수: 함수라고 할 수 있음, 지금까지 사용하던 f(x)=x2 와 같은 형태로 표기하지 않을 뿐 확률분포: 확률변수가 어떻게 행동할 것인지를 나타내는 개념 (확률분포는 확률변수가 취할 수 있는 모든 값과 그 값들이 나타날 확률을 표현한 것) 표본공간 S가 있고 S 내부에 가능한 여러 결과가 있다고 생각하자. 확률변수는 각 결과에 숫자를 배정하는 함수로 생각할 수 있음 (주사위의 경우 1~6) 확률변수 X에서 X=6 위 표현은 확률변수 X에 6을 할당하는 개념보다 Event 자체로 이해하는 것이 옳다. 확률변수 X를 시행이 성공하면 1, 시행이 실패하면 0이라고 정의해보자. 일단 S 내부의 결과(ex.시행이 성공)에 1이라는 숫자를 부여하는 함수로 X를 생각할 수 있다. 시행의 성공확률..
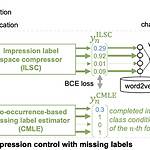 Font Generation with Missing Impression Labels
Font Generation with Missing Impression Labels
Seiya Matsuda, Akisato Kimura, Seiichi Uchida, Kyushu Univ., NTT, (2022.03) Abstract impression labeling 된 dataset을 사용하여 specific impression fonts를 GAN으로 생성하는 것이 목표 Main difficulty font impression은 애매 특정 impression label이 없다고 그 폰트가 해당 impression에 해당하지 않는 것이 아님 (dataset이 불안정) Key Idea co-occurrence-based missing label estimate impression label space compressor MyFonts 데이터셋은 전문가 + 비전문가가 tagging 한 ..
 VAE: Auto-Encoding Variational Bayes
VAE: Auto-Encoding Variational Bayes
Diederik P. Kingma, Max Welling, Machine Learning Group Universiteit van Amsterdam. (2013) Abstract intractable posterior, large dataset, continous latent variable 환경에서 directed probabilistic model의 추론, 학습을 어떻게 효율적으로 할 수 있을까? mild 한 미분 가능 조건하에 intractable case에서도 가능하며 large dataset을 다룰 수 있는 stochastic variational inference와 학습 알고리즘을 제시 Contribution variational lower bound에 reparameterization을 적용..
 ConvMixer: Patches Are All You Need?
ConvMixer: Patches Are All You Need?
Asher Trockman, J.Zico Kolter. Carnegie Mellon University and Bosch Center for AI. (2022.01.24) Abstract CNN이 vision task에서 지배적인 아키텍처였으나 최근 ViT가 SOTA를 달성 self-attentoin의 quadratic runtime의 한계로 large images를 처리하기 위해 patch embedding을 사용한다. 여기서 질문, ViT의 성능은 Transformer 아키텍처로 인한 것인가? 아니면 input representation으로 patch를 사용한 것이 영향을 끼쳤는가? 논문은 후자에 대한 증거를 제시한다 patch를 바로 input으로 받는 MLP-Mixer, 같은 resolution을..
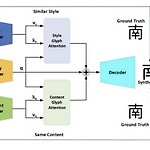 GANet: Glyph-Attention Network for Few-Shot Font Generation
GANet: Glyph-Attention Network for Few-Shot Font Generation
Under review as a conference paper at ICLR 2022 Mingtao Guo, Wei Xiong, Zheng Wang, Yong Tang, Ting Wu. Xian Univ. (2021.09) Abstract Non-local neural network에서 영감을 받아 제시한 GANet content encoder와 style encoder는 content glyph과 style glyph에서 key와 value를 추출 기존 SOTA few-shot font 생성 모델을 뛰어넘는 결과 Introduction 중국 폰트에 대한 인기가 세계적으로 증가하면서 니즈또한 증가하고 있음 그러나 폰트 생성은 노동집약적이며 오랜시간이 걸림 image to image translation과..
 AdaConv: Adaptive Convolutions for Structure-Aware Style Transfer
AdaConv: Adaptive Convolutions for Structure-Aware Style Transfer
Prashanth Chandran, Gaspard Zoss, Paulo Gotardo, Markus Gross, Derek Bradley. DisneyResearch, Department of Computer Sceince ETH Zurich. (2021). CVPR Abstract Style Transformer는 content image의 content를 유지하며 style image의 style을 입히는 CNN의 artistic 적용 SOTA neural style transfer는 style image의 통계적 특성을 content image에 옮기는 AdaIN AdaIN은 global operation으로 local geometric structure를 무시하고 transfer 시키지 못하는 문..
 CGAN: Conditional Generative Adversarial Nets
CGAN: Conditional Generative Adversarial Nets
Mehdi Mirza, Simon Osindero.(2014.11) Abstract Generative Adversarial Nets(이하 GAN)은 최근(2014.06) 생성 모델을 학습하기 위한 새로운 방식으로 제시되었음. y label을 generator와 discriminator에게 주어 GAN이 conditional 생성을 가능하게 함. MNIST를 class label에 따라 생성, multi-modal model로 training label이 없는 image에 대해 tagging 결과를 수록 1. Introduction GAN은 다루기 힘든 여러 확률적 계산을 근사하기 위한 생성모델 학습 프레임워크로 최근에 제시되었음. Markov chain을 사용하지 않고 역전파로만 gradient를 ..
 StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN
StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila NVIDIA. (2019.12) Abstract StyleGAN은 unconditional data-driven 이미지 생성 SOTA 달성 모델 StyleGAN의 특징적인 아티팩트를 분석하고 이를 해결하기 위한 아키텍처와 학습방법을 제안 generator의 normalization을 새로 디자인, progressive growing을 재고(resolution을 증가시키며 학습하는 것), generator regularization을 통해 latent code에서 image로의 매핑을 개선 path length regularizer는 이미지 퀄리티를 개선할..
 StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks
Tero Karras, Samuli Laine, Timo Aila. NVIDIA. (2019.03) Abstract style transfer 논문의 아이디어를 차용한 아키텍처를 제시 새 아키텍처는 비지도 학습으로 자동으로 학습되며, high-level attributes(pose, identity)와 생성 이미지의 stochastic variation(주근깨, 머리카락)을 separation, 직관적인 scale에 따른 생성 이미지 조정 또한 가능 기존 distribution quality metrics에서 SOTA를 달성, 입증 가능한 더 나은 interpolation 성능, variation의 latent factor를 더 잘 disentangle interpolation 퀄리티와 disentang..
 ConvNeXt: A ConvNet for the 2020s
ConvNeXt: A ConvNet for the 2020s
[convnext] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie, Facebook AI Research (FAIR), UC Berkeley (2022.01.02) Abstract 2020년도에 ViT는 이미지 분류 SOTA 모델로 CNN을 대체 하지만 vanilla ViT는 object detection 또는 semantic segmentation과 같은 general computer vision task에 적용하는데 어려움을 겪음 Swin Transformer와 같은 계층적 Transformer는 여러 vision task에서 좋은 성능을 냄 하지만 이러한 hybrid 접근의 유효성은 c..
 MLP-Mixer: An all-MLP Architecture for Vision
MLP-Mixer: An all-MLP Architecture for Vision
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy. Google Research, Brain Team. (2021.05) Abstract CNN은 vision task에서 널리 사용되었음, 최근에는 ViT와 같이 attention-based networks도 사용 convolution과 attention는 좋은 성능을 내기 위한 필수조건이 아님 오직 multi-layer perceptrons을 사용한 MLP-..
VAE는 생성을 목표로 하는 모델로 AE와 형태는 비슷하나 근간은 명백하게 다르다. 생성모델의 목표는 주어진 dataset x 를 사용하여 density estimation을 통해 p(x)를 근사하는 것 generator를 구성하는 모든 parameter set을 θ 라고 하자 샘플링가능한 분포 z 에서 샘플링한 zi 는 decoder(generator)인 gθ 를 통과하여 데이터를 생성 생성결과 = gθ(x|z=zi) generator까지 고려하였을 때 최대화 해야하는 대상은 pθ(x|z) (parameter set θ 로 구성된 generator를 사용하였을 때 prior z 에서 x 를 생성할 확률) 샘플링..
 Few-shot Font Style Transfer between Different Languages
Few-shot Font Style Transfer between Different Languages
Chenhao Li, Yuta Taniguchi, Min Lu, Shin’ichi Konomi HDI Lab, Kyushu University. (2021) Abstract 적은 샘플로 언어 간 font style을 transfer 할 수 있는 FTransGAN을 제시 언어 간 font style transfer는 많이 연구되지 않았음 multi-level attention을 통해 local, global style을 capture English, Chinese를 모두 가진 847개의 font dataset을 사용 Introduction 폰트를 만드는 것은 매우 노동집약적, 대부분 하나의 언어에 대한 폰트만 만듦 폰트의 subset만 보고 나머지를 생성하는 것은 neural net으로 가능해졌으며 관련 ..
 DeiT: Training data-efficient image transformers & distillation through attention
DeiT: Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Herve Jegou. Facebook AI. Sorbonne University. (2020.12) Abstract Image task에 pure attention 기반 모델이 활용되지만 large dataset에서 pre-training이 필수적이며 이는 활용에 한계를 가져옴 single computer에서 3일 동안 ImageNet dataset만 학습하여 top-1 acc 83.1%를 달성 attention을 통해 학습하는 distillation token을 도입한 transformer를 위한 teacher-student strategy를 제시 ..
 CoAtNet: Marrying Convolution and Attention for All Data Sizes
CoAtNet: Marrying Convolution and Attention for All Data Sizes
Zihang Dai, Hanxiao Liu, Quoc V. Le, Mingxing Tan Google Research, Brain Team (2021.06) Abstract Transformer 아직 vision task에서 SOTA convolutional network보다 성능이 떨어짐 Transformer는 더 큰 capacity를 가지지만 inductive bias의 부족으로 일반화 성능이 convolutional network에 비해 떨어짐 두 아키텍처의 장점을 결합하기 위해 hybrid model인 CoAtNets를 제시 CoAtNet의 key insights depthwise Convolution, Self-Attention은 간단한 relative attention을 통해 결합 가능 수직으..
 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo Microsoft Research Asia (2021.03) Abstract CV task를 위한 범용적인 Backbone 모델로 새로운 vision Transformer인 Swin Transformer를 제시 vision에 Transformer를 사용하기에는 visual entities의 scale 변동, high resolution pixels 등의 어려움이 있음 이를 해결하기 위해 Shifted windows를 사용하는 hierarchical Transformer를 제시 shifted windowing은 겹치지 않는 local window 한정으..
 MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Mark Sandler Andrew Howard Menglong Zhu Andrey Zhmoginov Liang-Chieh Chen Google Inc. CVPR Abstract 다양한 task, model size에서 mobile model SOTA를 달성한 MobileNetV2를 제시 SSDLite를 사용한 object detection, DeepLabv3 기반 semantic segmentation에서 MobileNetV2를 사용 thin bottle neck layers 간 shortcut connection에서 inverted residual structure를 사용 intermediate expansion layer는 lightweight depthwise convolution을 사용 narr..
 Residual Attention Network for Image Classification
Residual Attention Network for Image Classification
Fei Wang1, Mengqing Jiang2, Chen Qian1, Shuo Yang3, Cheng Li1,Honggang Zhang4, XiaogangWang3, Xiaoou Tang, SenseTime Group Limited, Tsinghua University,The Chinese University of Hong Kong, Beijing University of Posts and Telecommunications. (2017) Abstract 당시 SOTA인 attention mechanism을 CNN에 사용한 Residual Attention Network를 제시 Residual Attention Network(이하 RAN)은 attention-aware feature를 뽑아내는 Atten..